
深入存储证明:实现跨时间、跨链的区块链状态感知
撰写:LongHash Ventures
编译:深潮 TechFlow
如果你每小时都失去记忆,需要不停询问别人告诉你做过什么事怎么办?这就是智能合约目前所处的状态。在以太坊这样的区块链上,智能合约无法直接访问超过 256 个区块之外的状态。这个问题在多链生态系统中更加严重,跨不同执行层检索和验证数据甚至更加困难。
2020 年,Vitalik Buterin 和 Tomasz Stanczak 提出了一种跨时间访问数据的方法。虽然这一 EIP 方案陷入了停滞,但它的需求在以 Roll-up 为中心的多链世界中重新出现。如今,存储证明已经成为前沿领域,以赋予智能合约意识和记忆。
访问链上数据的方式
Dapp 可以通过多种方式访问数据和状态。所有这些方法都需要应用程序对人类/实体、加密经济安全性或代码进行一定程度的信任,并都存在一定的权衡取舍:
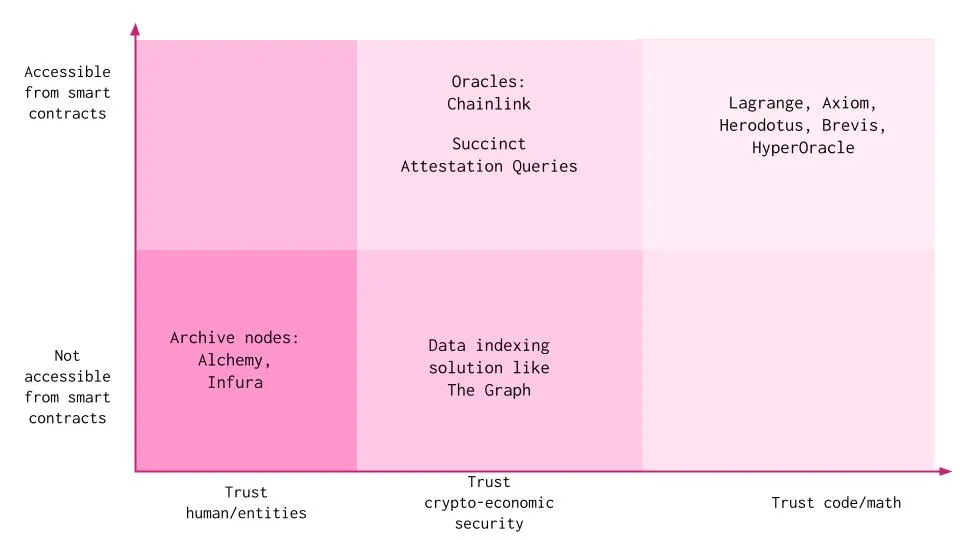
信任人类/实体:
存档节点:操作者可以自己运行存档节点,或者依赖 Alchemy、Infura 等存档节点服务提供商,访问从创世块开始的所有数据。它们提供与全节点相同的数据,还包括整个区块链的所有历史状态数据。链下服务如 Etherscan 和 Dune Analytics 使用存档节点访问链上数据。链下参与者可以证明这些数据的有效性,链上智能合约可以验证数据是由可信参与者/委员会签名的。但是底层数据的完整性无法被验证。这种方法需要 Dapp 信任存档节点服务提供商以正确的方式运行基础设施,没有任何恶意意图。
信任加密经济安全性:
- 索引器:索引协议组织区块链上的所有数据,允许开发者构建和发布开放 API,以便应用程序可以查询。单个索引器是质押代币以提供索引和查询处理服务的节点操作者。但是,当提供的数据不正确时,可能会发生争议,仲裁过程需要时间。此外,来自 The Graph 等索引器的数据不能被直接利用在智能合约的业务逻辑中,而是被用于基于 web2 的数据分析背景中。
- 预言机:预言机服务提供商使用从许多独立节点操作者那里汇总的数据。这里的挑战在于,从预言机获得的数据可能不会被频繁更新,范围也有限。像 Chainlink 这样的预言机通常只维护特定状态,比如价格信息,对于应用程序特定状态和历史的数据则不可行。此外,这种方法也会在数据中引入一定程度的偏差,需要信任节点运营商。
信任代码:
- 特殊变量和函数:像以太坊这样的区块链具有特殊变量和函数,主要用于提供关于区块链的信息,或者是通用实用函数。智能合约只能访问最近 256 个区块的区块哈希。出于可扩展性的原因,并非所有区块的区块哈希都是可用的。能够访问历史区块哈希将非常有用,因为它可以允许针对它们进行证明的验证。EVM 执行环境中没有可以访问旧区块内容、之前交易内容或收据输出的操作码,所以节点可以安全地忘记这些内容,并仍能处理新区块。这种方法也仅限于单个区块链。
鉴于这些解决方案的挑战和局限性,显然存在对链上存储和提供区块哈希的明确需求。这就是存储证明的用武之地。为了更好地理解存储证明,我们快速看一下区块链中的数据存储。
区块链中的数据存储
区块链是一个公共数据库,在网络中的许多计算机之间更新和共享。数据和状态以连续的区块组存储,每个区块通过存储前一个区块头的哈希来加密引用其父区块。
以以太坊区块为例。以太坊使用一种特殊的 Merkle 树,称为“Merkle Patricia Tree”(MPT)。以太坊区块头包含四个不同的 Merkle -Patricia 树的根,即状态树、存储树、收据树和交易树。这四棵树对包含所有以太坊数据的映射进行编码。使用 Merkle 树是由于其在数据存储中的高效性。通过递归哈希,最终只需要存储根哈希,节省了大量空间。它们允许任何人通过证明递归哈希节点导致相同的根哈希,来证明树中元素的存在。Merkle 证明允许以太坊上的轻客户端通过回答以下问题来获取答案:
- 这个交易存在于某个特定区块中吗?
- 我的账户当前余额是多少?
- 这个账户存在吗?
与下载每个交易和每个区块不同,“轻客户端”只能下载区块头链,并使用 Merkle 证明来验证信息。这使整个过程非常高效。
请参阅Vitalik 和 Maven11 的这篇博客研究文章,更好地理解与 Merkle 树相关的实现、优点和挑战。
存储证明
存储证明允许我们使用加密证明来证明某件事被记录在数据库中且有效。如果我们能提供这样的证明,那就是一个可验证的声明,证明某件事发生在区块链上。
存储证明可以实现什么?
存储证明允许两个主要功能:
- 访问最后 256 个区块之外的历史链上数据,一直回到创世块
- 在一个区块链上访问另一个区块链的链上数据(历史和当前),借助共识验证或 L2 桥接(针对 L2)
存储证明的工作原理是什么?
简单来说,存储证明检查特定区块是否是区块链的规范历史的一部分,然后验证所请求的特定数据是否是区块的一部分。这可以通过以下方式实现:
- 链上处理:Dapp 可以获取初始可信区块,将区块作为 Calldata 传递以访问前一个区块,一直遍历回创世块。这需要大量的链上计算和大量的 Calldata。由于需要海量的链上计算,这种方法完全不切实际。Aragon 在 2018 年尝试使用链上方法,但由于高昂的链上成本而不可行。
- 使用零知识证明:方法类似于链上处理,不同之处在于使用零知识证明将复杂计算转移到链下。
访问同一链的数据:可以使用零知识证明断言任意历史区块头是执行环境中可访问的最近 256 个区块头的祖先之一。另一种方法是索引源链的全部历史并生成零知识证明以证明索引正确完成。该证明会随源链的新区块添加而定期更新。
- 访问跨链数据:提供者在目标链上收集源链的区块头,并使用零知识共识证明证明这些区块头的有效性。也可以使用现有的跨链消息传递解决方案,如 Axelar、Celer 或 LayerZero 来查询区块头。
- 在目标链上维护源链的区块头哈希缓存,或链下区块哈希累加器的根哈希。这个缓存定期更新,用于在链上高效证明给定的区块存在且与可从状态访问的最近的区块哈希具有加密链接。这个过程称为证明链的连续性。也可以使用专用区块链来存储所有源链的区块头。
- 根据 Dapp 在目标链上的请求,从链下索引数据或链上缓存(取决于请求的复杂性)访问历史数据/区块。 缓存的区块头哈希在链上维护,而实际数据可能存储在链下。
- 通过 Merkle 包含证明检查指定区块中是否存在数据,并为此生成零知识证明。该证明与正确索引的零知识证明或零知识共识证明相结合,并在链上提供以进行无需信任的验证。
- 然后 Dapp 可以在链上验证该证明,并使用数据执行所需操作。除了验证零知识证明,公共参数(如区块号和区块哈希)也与在链上维护的区块头缓存进行检查。
采用这种方法的项目有 Herodotus、Lagrange、Axiom、HyperOracle、Brevis Network 和 nil 基金会。尽管正为使应用程序跨多个区块链具有状态意识而做出重大努力,但 IBC(链间通信)作为一种互操作性标准脱颖而出,支持应用程序使用如 ICQ(跨链查询)和 ICA(跨链帐户)。 ICQ 使 Chain A 上的应用程序可以通过在简单的 IBC 数据包中包含查询来查询 Chain B 的状态,ICA 允许一个区块链安全控制另一个区块链上的账户。将它们组合在一起可以支持有趣的跨链用例。像 Saga 这样的 RaaS 提供商会默认使用 IBC 为所有应用链提供这些功能。
存储证明可以通过多种方式进行优化,以在内存消耗、证明时间、验证时间、计算效率和开发者体验之间找到最佳平衡。整个过程可以大致分为 3 个主要子过程:
- 数据访问;
- 数据处理;
- 数据访问和处理的零知识证明生成。
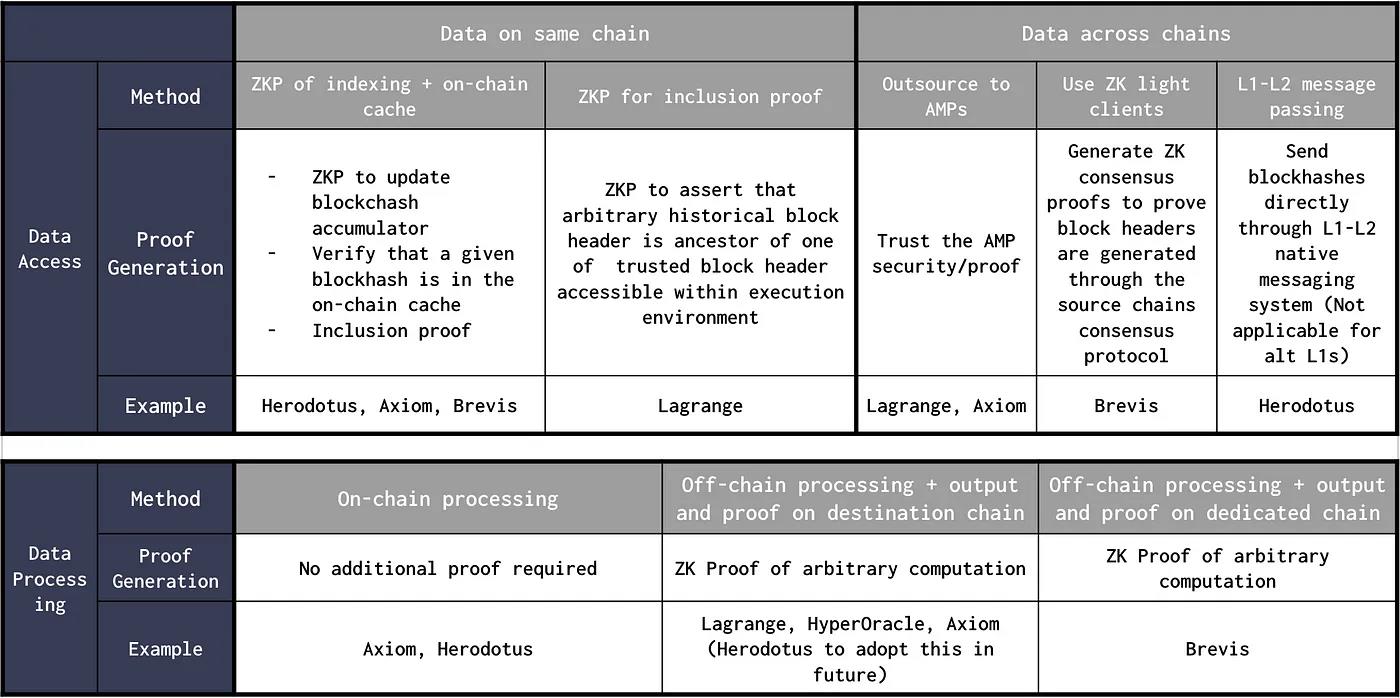
数据访问:在这个子过程中,服务提供商以原生方式在执行层访问源链的区块头,或通过维护链上缓存。对于跨链的数据访问,需要在目标链上验证源链共识。采用的方法和优化包括:
- 现有以太坊区块链:可以使用以太坊区块链的现有结构,利用零知识证明证明相对于当前区块头的任意历史存储插槽的值。这可以视为一个大型包含证明。也就是说,给定最近的区块头 X 在高度 b,存在区块头 Y 在高度 b-k 是 X 的祖先。这基于以太坊共识的安全性,需要高效的证明系统。这是 Lagrange 采用的方法。
- 链上 Merkle Mountain Ranges (MMR) 缓存:Merkle Mountain Range 可以看作是 Merkle 树列表,当两个树达到相同大小时组合起来。MMR 中的单个 Merkle 树通过将父节点添加到树的先前根来组合。MMR 与 Merkle 树类似,具有一些额外优点,例如有效地追加元素和高效的数据查询,特别是从大型数据集读取顺序数据。通过 Merkle 树追加新头需要在每个级别传递所有姐妹节点。为了有效地追加数据,Axiom 使用 MMR 在链上维护区块头哈希的缓存。Herodotus 在链上存储 MMR 区块哈希累加器的根哈希。这使他们能够通过包含证明检查所获取的数据与这些区块头哈希。这种方法需要定期更新缓存,如果不去中心化会带来活跃性问题。
- 为了优化效率和计算成本,Herodotus 维护两种不同的 MMR。 根据特定的区块链或层,累加器可以使用不同的哈希函数进行定制。对 Starknet 进行证明时可能使用 poseidon 哈希,但对 EVM 链使用 Keccack 哈希。
- 链下 MMR 缓存:Herodotus 维护链下缓存之前获取的查询和结果,以便在再次请求数据时能更快获取。这需要比仅运行存档节点更多的基础设施。 在链下基础设施上的优化潜在地可以为终端用户减少成本。
- 专用区块链用于存储:Brevis 依靠专用的零知识 rollup(聚合层)来存储其证明的所有链的所有区块头。如果没有这个聚合层,每个链都需要存储每个其他链的区块头,这将导致对于 N 条区块链有 O(N2)“连接”。通过引入聚合层,每个区块链只需要存储 rollup 的状态根,将总体连接降低到 O(N)。该层还用于聚合多个区块头/查询结果证明,并在每个连接的区块链上提交单个验证证明。
- L1-L2 消息传递:由于 L2 支持通过 L1 更新 L2 合约的原生消息传递,所以可以避免源链共识验证。缓存可以在以太坊上更新,L1-L2 消息传递可以用于将链下编译的区块哈希或树根发送到其他 L2。Herodotus 正在采用这种方法,但这对于 alt L1 不可行。
数据处理:
除了访问数据,智能合约还应该能够对数据进行任意计算。虽然一些用例可能不需要计算,但对许多其他用例来说,这是一个重要的增值服务。许多服务提供商支持以零知识证明的形式对数据进行计算,并在链上提供该证明以验证其有效性。因为现有的跨链消息传递解决方案如 Axelar、LayerZero、Polyhedra Network 可能被用于数据访问,因此数据处理可能会成为存储证明服务提供商的一个差异化点。
例如,HyperOracle 允许开发者使用 JavaScript 定义自定义的链下计算。Brevis 设计了一个开放的零知识查询引擎市场,接受来自 Dapp 的数据查询,并使用证明过的区块头对其进行处理。智能合约发送数据查询,由市场上的证明者获取。证明者基于查询输入、相关的区块头(来自 Brevis 聚合层)和结果生成证明。Lagrange 引入了零知识大数据技术栈,用于证明分布式编程模型如 SQL、MapReduce 和 Spark/RDD。这些证明是模块化的,可以由来自现有跨链桥接和跨链消息传递协议的任何区块头生成。Lagrange 零知识大数据技术栈的第一个产品是零知识 MapReduce,这是一个用于证明涉及大量多链数据计算结果的分布式计算引擎(基于著名的 MapReduce 编程模型)。例如,单个零知识 MapReduce 证明可以证明部署在 4-5 条链上的 DEX 在指定时间窗口内的流动性变化。对于相对简单的查询,计算也可以像 Herodotus 目前所做的那样直接在链上完成。
证明生成:
- 可更新证明:当需要对移动的区块流计算和有效维护证明时,可以使用可更新证明。当新的区块被创建时,为了维护合约变量(如代币价格)的移动平均证明,可以高效更新现有证明,而不需要从头重新计算新的证明。为了证明链上状态的动态数据并行计算,Lagrange 在 MPT 的一部分之上构建了一个批量向量承诺,称为 Recproof,实时更新它,并对其进行动态计算。通过在 MPT 之上递归创建 Verkle 树,Lagrange 能够高效计算大量动态链上状态数据。
- Verkle 树:与 Merkle 树不同,Merkle 树需要提供所有共享父节点的节点,Verkle 树只需要根路径。与 Merkle 树中的所有姐妹节点相比,这条路径要小得多。以太坊也在考虑在未来版本中使用 Verkle 树来最小化以太坊全节点需要持有的状态量。Brevis 利用 Verkle 树在聚合层存储证明过的区块头和查询结果。它大大减小了数据包含证明的大小,特别是当树包含大量元素时,并支持高效包含证明批量数据。
- 内存池监控以加快证明生成:Herodotus 最近发布了 turbo,允许开发者在智能合约代码中添加几行代码来指定数据查询。Herodotus 监控与 turbo 合约交互的智能合约交易的内存池。当交易在内存池本身时,证明生成过程就开始了。一旦证明在链上生成和验证,结果就被写入链上 turbo 交换合约。只有通过存储证明进行身份验证后,结果才能被写入 turbo 交换合约。一旦发生这种情况,交易费用的一部分就与排序器或区块生成者共享,激励他们等待更长时间以收取费用。对于简单的数据查询,所请求的数据可能在用户的交易被包含在区块之前就已经在链上可用。
状态/存储证明的应用
状态和存储证明可以为应用层、中间件和基础设施层的智能合约解锁许多新的用例。其中一些是:
应用层:
治理:
- 跨链投票:链上投票协议可以允许 Chain B 上的用户证明在 Chain A 上拥有资产。用户不需要桥接他们的资产才能在新的链上获得投票权。例如:Herodotus 上的 SnapshotX
- 治理代币分发:应用可以向活跃用户或早期采用者分发更多的治理代币。例如:Lagrange 上的 RetroPGF。
身份和声誉:
- 所有权证明:用户可以证明在链 A 上拥有某个 NFT、SBT 或资产,从而在链 B 上执行某些操作。例如,游戏应用链可以决定在其他有现有流动性的链上像以太坊或任何 L2 启动其 NFT 收藏。这将允许游戏利用其他地方存在的流动性,而实际上不需要跨链 NFT。
- 使用证明:用户可以根据其在平台上的历史使用情况(证明用户在 Uniswap 上交易了 X 量)获得折扣或高级功能。
- OG 证明:用户可以证明他/她拥有一个活跃账户,该账户的天数超过 X 天。
- 链上信用评分:一个跨链信用评分平台可以汇总单个用户的多个账户的数据以生成信用评分。
上述所有证明都可以用于向用户提供定制体验。Dapp 可以提供折扣或特权来保留有经验的交易员或用户,并为新手用户提供简化的用户体验。
Defi:
- 跨链借贷:用户可以在链 A 上锁定资产,而在链 B 上获得贷款,而不需要桥接代币。
- 链上保险:可以通过访问历史链上数据来确定故障,保险赔付可以完全在链上完成。
- 资产在池中的时间加权平均价格:应用可以计算并获取资产在指定时间段内 AMM 池中的平均价格。 例如:Axiom 上的 Uniswap TWAP 预言机。
- 期权定价:链上期权协议可以使用资产在去中心化交易所过去 n 个区块上的波动性来对期权进行定价。
最后两个用例将需要在源链中添加新区块时更新证明。
中间件:
- 意图:存储证明将允许用户对意图更具表现力和明确。虽然求解器的工作是执行必要的步骤以满足用户的意图,但用户可以根据链上数据和参数更清楚地指定条件。求解器还可以证明找到最佳解决方案所利用的链上数据的有效性。
- 账户抽象:用户可以利用存储证明根据来自其他链的数据设置规则。例如:每个钱包都有一个 nonce。我们可以证明一年前 nonce 是一个特定的数字,目前 nonce 与之相同。这可以被用来证明这个钱包根本没有被使用过,然后可以将钱包的访问权委托给另一个钱包。
- 链上自动化:智能合约可以根据依赖链上数据的预定义条件自动执行某些操作。自动化程序需要定期调用智能合约以维持 AMM 的最佳价格流动或通过避免不良债务来保持借贷协议的健康。HyperOracle 支持自动化以及链上数据访问。
基础设施
- 无需信任的链上预言机:去中心化的预言机网络汇总来自预言机网络内多个单独预言机节点的响应。预言机网络可以消除这种冗余,利用加密安全性实现链上数据。预言机网络可以将来自多个链(L1、L2 和 alt L1)的数据汇集到单个链上,并简单地使用存储证明证明其他地方的存在。取得重大进展的 DeFi 解决方案也可以使用定制解决方案。例如,最大的流动性质押提供者 Lido Finance 已经与 Nil Foundation 合作,资助 zkOracle 的开发。这些解决方案将实现对 EVM 历史数据的无需信任的数据访问,并保护 Lido Finance150 亿美元的已抵押以太坊流动性。
- 跨链消息传递协议:现有的跨链消息传递解决方案可以通过与存储证明服务提供商合作来增加其消息的表达能力。这是 Lagrange 在其模块化论文中建议的方法。
结论
意识让科技公司能够更好地为客户服务。 从用户身份到购买行为再到社交关系,科技公司利用认知来解锁精准定位、客户细分和病毒营销等功能。传统的科技公司需要用户的明确许可,在管理用户数据时必须谨慎行事。但是,许可区块链上的所有用户数据都是公开的,不一定会泄露用户身份。智能合约应该能够利用公开可用的数据来更好地为用户服务。更专业生态系统的发展和采用,将使跨时间和跨链的状态意识成为一个越来越重要的问题。存储证明可以使以太坊作为身份和资产所有权层出现,而不仅仅是一个结算层。用户可以在以太坊上维护自己的身份和关键资产,这可以在多个区块链中使用,而不需要始终桥接资产。我们对未来会解锁的新可能性和用例保持兴奋。


.jpg){kind=link}