
Ordinal铭文协议的原理与技术细节讨论
最近两周我在研究BTC生态和各种铭文项目的时候,发现很少有文章能够清晰地把原理和技术细节介绍的清楚:比如铭文在铸造的时候,交易是如何发起的,UTXO里面的sats到底是怎么被追踪的,铭刻的内容到底是放在脚本什么地方,以及BRC20在转账的时候为何需要两次操作?我发现不了解这些技术细节,就很难搞明白 BRC20,BRC420,atomicals, stamps, 符文Runes这些各种协议的区别,本文将深入到BTC区块链的基础知识,试着回答上述问题。
BTC的区块结构
区块链本质是一种多用户记账技术,用计算机科学术语来说,是一种分布式数据库,每一段时间内的记录(账目)组成一个区块,然后根据时间先后顺序进行账本扩展。
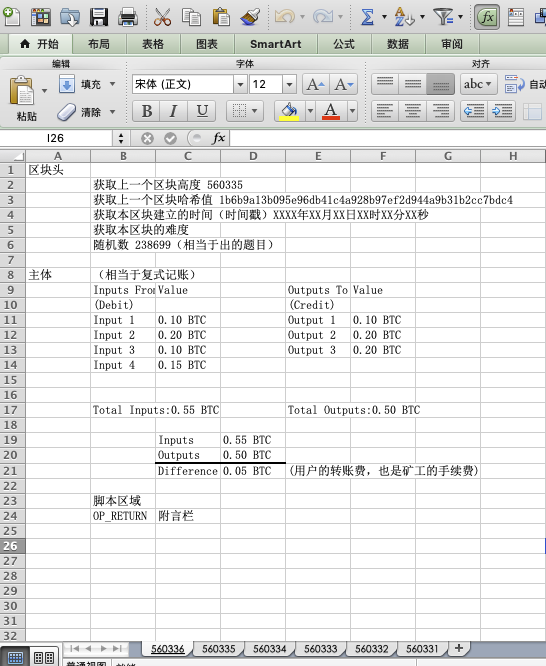
我们用excel做了表格来说明区块链的工作原理。一份excel文件代表了一个区块链,其中每一个单独表格表示一个个区块,区块按照时间顺序从560331,560332.一直到最新的560336. 560336会在区块内打包最近的交易。区块内部主体部分就是我们在会计领域最常见的复式记账法,一边地址记做借出(debit)就是inputs from,另一边地址记做贷入(credit)就是outputs to。Value对应相应地址的BTC数量。Inputs的币的数量会大于Outputs币的数量,差额就是用户层面的转账费,也是矿工(记账人)的取得的手续费。区块头部会获取上一个区块高度,上一个区块的哈希值,本区块的建立时间(时间戳),和随机数。那么做为去中心化的记账技术,到底是谁来抢到下一个区块的记账权呢?靠的就是这个随机数和与之对应的哈希值。拥有算力的矿工通过对当前区块的随机数进行哈希计算,最先得到符合条件哈希值的矿工拥有下一个区块的记账权并且赢得区块奖励和转账费。最后是脚本区域,可以用来做一些扩展应用,比如脚本op_return可以当做附言栏。需要注意的是,在实际的区块中,脚本区是附着在input和output信息中的,而不是真的另外单独一个区域。比如附着在input的脚本是解锁脚本(ScriptSig),需要钱包地址进行私钥签名授权允许转出,而附着在output的脚本是锁定脚本(ScriptPubKey),用来设置收到该BTC的解锁条件(一般情况条件就是“有相应私钥的人才能消费”)。
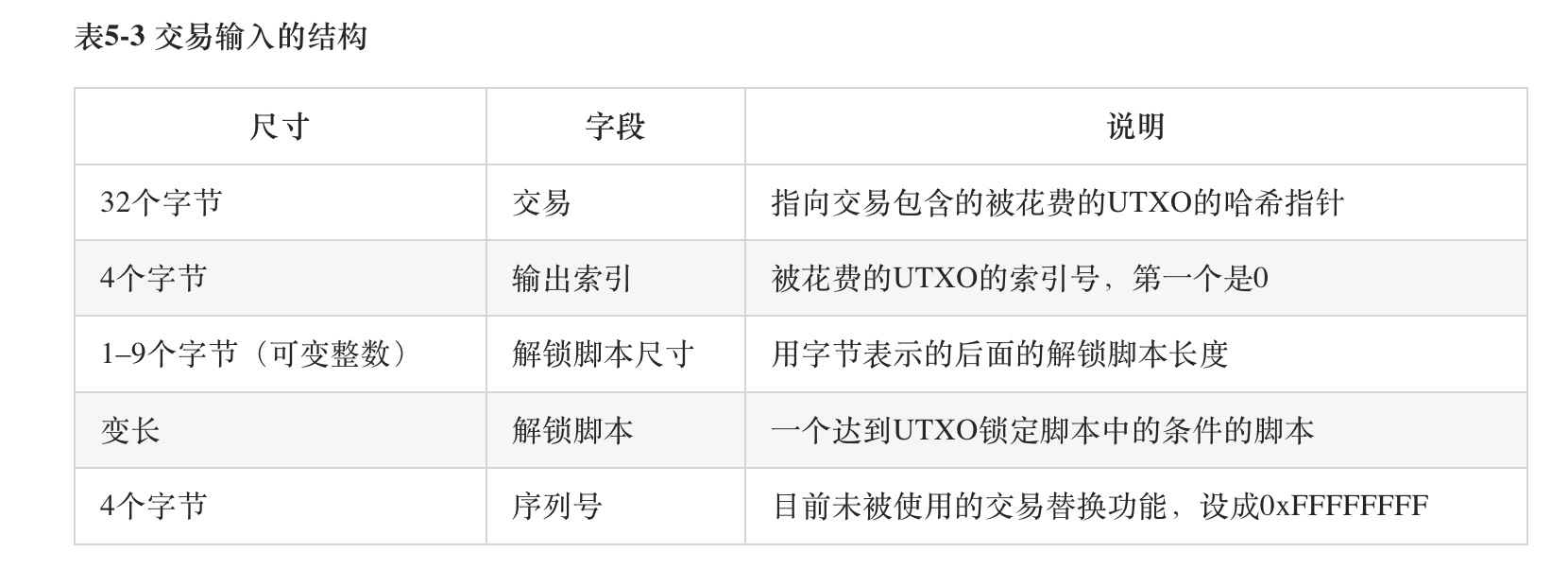
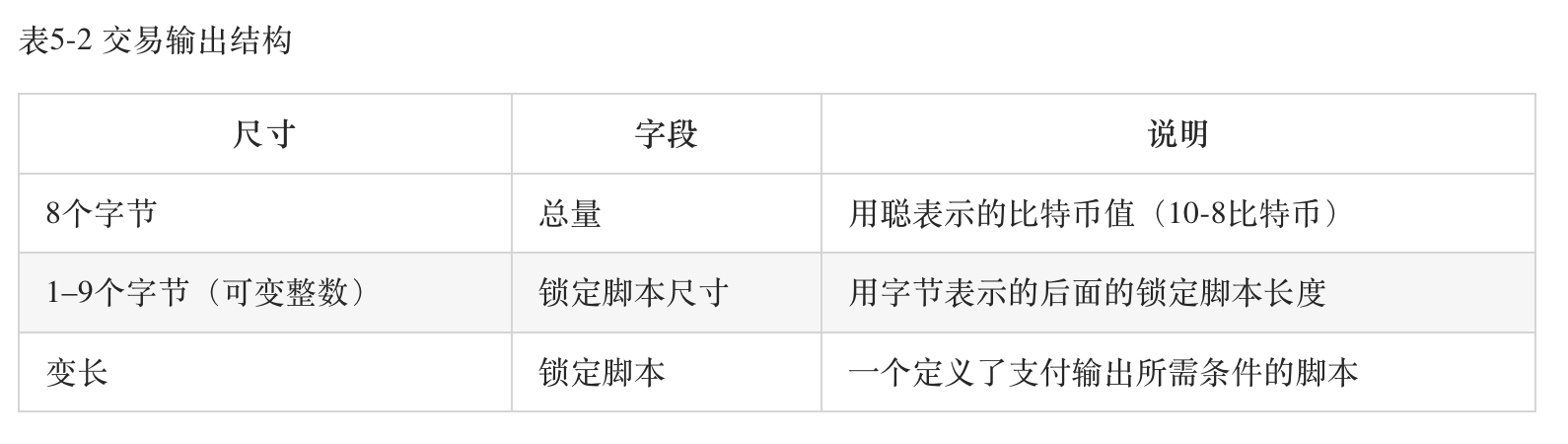
上面两张图是原始的input和output的数据结构表,在执行层面,脚本表现为交易信息的附带参数,其中解锁脚本(ScriptSig)因为需要私钥授权,也被称为“见证数据”(witness data)。
隔离见证和Taproot
尽管比特币网络已经运行了超过10年,没有发生过什么显著的事件,但曾多次出现交易成本飙升到不再可行的高点。因此,比特币的开发人员一直在讨论如何最好地扩展网络,以处理未来不断增长的交易量。
2017年,这场辩论达到高潮,比特币开发社区分裂成两派,一派是支持使用软分叉实施名为SegWit的功能,另一派是支持直接区块扩容的“大区块”派。
我们在上文提到了解锁脚本需要用到私钥授权生成“见证数据”,那么是不是可以把这个见证数据从区块中分离,从而变相增加每个区块可容纳的交易数呢?隔离见证(Segregated Witness)在2017年8月激活正式激活。它的实现方式正是将所有的交易数据分为两部分,一部分是交易的基本信息(Transaction Data),另一部分是交易的签名信息(Witness Data),并把签名信息保存在一个新的数据结构中,是被称为“隔离见证(witness)”的新区块中,并与原始交易分开传输。
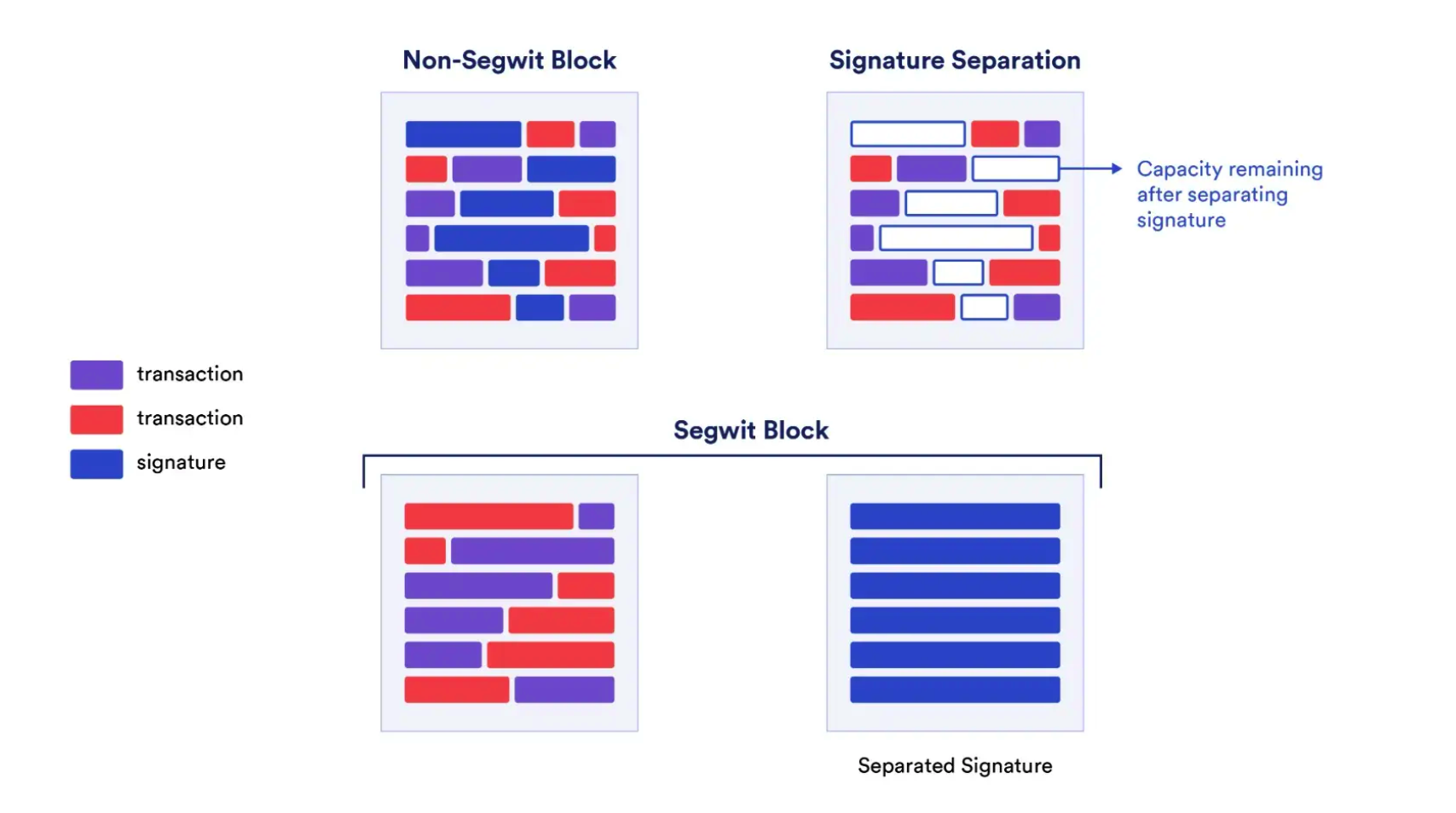
在技术上,SegWit的实施意味着交易不再需要包括见证数据(不会占用比特币原本为区块安排的 1MB 空间)。取而代之的是,在一个区块的末尾,为见证数据创建了一个额外独立的空间。它支持任意的数据转账,并有一个折扣的 "区块重量(block weight)",巧妙地将大量的数据保持在比特币的区块大小限制内,以避免硬分叉的需要。这样,比特币交易的交易数据大小提高了上限,同时降低了签名数据的交易费用。在SegWit升级之前,比特币的容量上限是1MB,而SegWit之后,虽然单纯交易的容量上限仍旧是1M,但隔离见证空间的大小达到了4MB。
Taproot 于2021年11月实施,由 3 项不同的比特币改进提案 (BIP) 组成,其中包括:Taproot、Tapscript 及其名为「Schnorr 签名」的全新数字签名方案。Taproot 旨在为比特币用户带来诸多好处,例如提升交易私密性和降低交易费用。还将让比特币执行更多复杂的交易,从而拓宽应用场景(新增加了一些操作码opcodes)。
这些更新是 Ordinals NFT的关键推动因素,它将NFT数据存储在 Taproot 脚本路径的花费脚本(spent script)中(见证数据空间)。这次升级使得结构化和存储任意的见证数据变得更加容易,为 "ord" 标准奠定了基础。随着数据要求的放宽,假设一个交易可以用其交易和见证数据填满整个区块 — 达到4MB的区块大小(见证数据空间)限制 — 极大地扩展了可以放在链上的媒体类型。
也许有人会问,既然在脚本中放入一些字符串,那对这些字符串没有限制条件吗?万一真的执行这些脚本呢?如果随便放内容,那会不会出现错误代码拒绝出块呢?这就要提到 OP_FALSE指令。OP_FALSE(在比特币脚本中也表示为“0”)确保脚本语言中的执行路径永远不会进入OP_IF分支,并保持未执行状态。它充当脚本中的占位符或空操作(No Operation),类似于高级语言中的“注释”,来保证后续的代码不被执行。
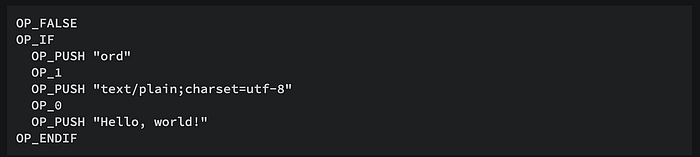
UTXO转账模型
以上都是从计算机数据结构方面来研究BTC的基本原理,我们再从金融模型方面来讨论一下UTXO模型。
UTXO是 Unspent Transaction Outputs 的缩写,中文翻译是“没有花掉的交易输出”,实际可以理解为在一次转账时剩余没有转出的资金。那比特币为啥要使用这么一个概念呢?这就要从记账方法的账户交易模型和账户余额模型说起了。
因为我们在中心化的体系待的太久,已经非常习惯账户余额模型的记账方式。当用户A给用户B转100块钱时,银行会先检查A的银行账户上是否有100元,如果有就从A的账户里扣除100元再在B的账户上加上100元,这样一笔转账就完成了。
然而,比特币的记账算法里没有余额这个概念。在区块链的分布式账本上记录的只有一笔笔的交易,并不会直接记录一个账户当前余额是多少(记录余额一般需要专门的服务器节点来记录,那就中心化了)。假设当前用户A余额是1000元,如果用户A给用户B转100元,这笔转账会被记录成:
交易1 用户A给用户B转账100元
交易2 用户A给用户A自己转账900元 (UTXO)

这里的交易2虽然是一笔交易,但从功能上来说他担当了账户余额的作用,表示在完成这笔100元转账后A的账户上还剩余900元。
那么问题来了,为啥非要造一个这样的UTXO呢?因为在BTC区块链上只能记录交易,没法记录账户余额。如果没有这个UTXO的话,要计算余额需要把一个账户的所有交易的入账和出账全部累加一遍,这是个非常消耗时间和计算资源的事情。而UTXO的出现巧妙的避免了在计算余额时要回溯所有交易的痛点问题。
UTXO 有个特点,就是跟硬币一样,不能掰开用,那么交易过程中如何凑够输入金额,又如何找零的呢?我们可以用硬币来做类比(实际上每次当你看到UTXO这个单词的时候请自动翻译成“硬币”比较好)。
小明给小刚转账1比特币。整个过程是这样的,小明要收集足够的input,比如小明的地址对应的以往交易中,找到了一个面值为0.9的 UTXO,不够1比特币,好在交易中是允许有多个输入的,所以小明又找到了一个面值0.2的 UTXO,这样在这次转账的交易中,就会有两个输入。同时输出也会有两个,一个是指向小刚地址,面值是1比特币。另一个指向小明自己的地址,面值是0.1比特币,这个输出就是找零了(这个例子忽略了gas)。
换句话说,小明口袋里面有两个硬币,一个面值0.9,另一个面值0.2,此时小明需要支付面值1的硬币,就需要同时把这两个硬币递给小刚,小刚收到后找零0.1给小明。所以这个记账模型的本质就是通过“找零”的动作来避免了“计算余额”。
Ordinal协议的排序系统
Ordinal协议可以说是本轮BTC生态爆发的源头,是把同质化的BTC分解成最小单位sat,然后对每一个sat标记一个序号。那是怎么做的呢?
我们知道,BTC的总量是2100万枚,一枚BTC最小可以拆分到一亿份(sat),所以BTC的最小单位就是sat,这些BTC也好,最小单位sat也好,都是典型的同质化代币FT。我们现在试着给这些sats分配一个序号(ordinal)。
前面在谈到区块数据结构的时候,我们提到交易信息需要注明input的地址和数额以及output的地址和数额。而每个区块是包含了两部分交易:BTC出块奖励和转账的手续费。手续费交易必然有input和output,但出块奖励因为是凭空生成的BTC,无input地址,所以这个“input from”的字段是空白的,也叫做“coinbase交易”。BTC总量的2100万枚都是来源于这个coinbase交易,也是所有区块中交易列表排列在第一位的。
Ordinal协议规定如下:
- 编号:每一个sat以他们被开采出来的顺序进行编号
- 转移:按照先进先出规则,从交易的输入转移到输出
第一条规则相对简单,它决定了编号只能由挖矿奖励中的coinbase交易生成。例如,若第一个区块的挖矿奖励为50个BTC,则第一个区块会分配出[0;1;2;…;4,999,999,999]范围的sats;第二个区块奖励也为 50 BTC 时,则第二个区块会分配出[5,000,000,000;5,000,000,001;…;9,999,999,999]范围的sats。

这里比较难理解的部分在于,由于UTXO实际上包含很多个聪,那么这个UTXO中的每一个聪看起来都一样,怎么给他们排序呢?这个实际上是第二条规则决定的,举一个简单的例子吧:
我先假设BTC的最小分割单位是1,总共出了10个区块,每个区块的出块奖励是10个BTC,即总量是100个。我们直接可以给这100个BTC赋予一个(0-99)的序号。如果没有任何转账情况,那我们只知道第一个区块的10个BTC编号是(0-9),第二个区块的10个BTC编号是(10-19),一直到第十个区块的10个BTC编号是(90-99)。这其中因为没有任何花费,也就没有任何output,我们就只能给每10个BTC赋予一个编号范围。
假设在第二个区块中加入两个支出(output),一个是3BTC,一个是“找零”的7 BTC,对应于给别人转账了3个BTC,再给自己找零7个BTC。此时在区块的交易列表中,假设给自己找零的7个BTC排名第一(对应的编号是10-16),给别人的3BTC排第二(对应的编号是17-19)。这就通过对output的的转移确认了某个UTXO所包含sats的顺序集合。
注意是每一个sat不是UTXO! 由于UTXO是不可再分的最小交易单元,因此sat只能存在于UTXO中,且UTXO包含了一定范围的sats,且只能在花费某一UTXO后产生新的输出中对sats编号进行拆分。
至于用什么方式来表达这个“编号”,Ordinal支持多种形式,比如上面提到的“整数法”,其他还有十进制小数法,度数法,百分比法,纯字母命名法。
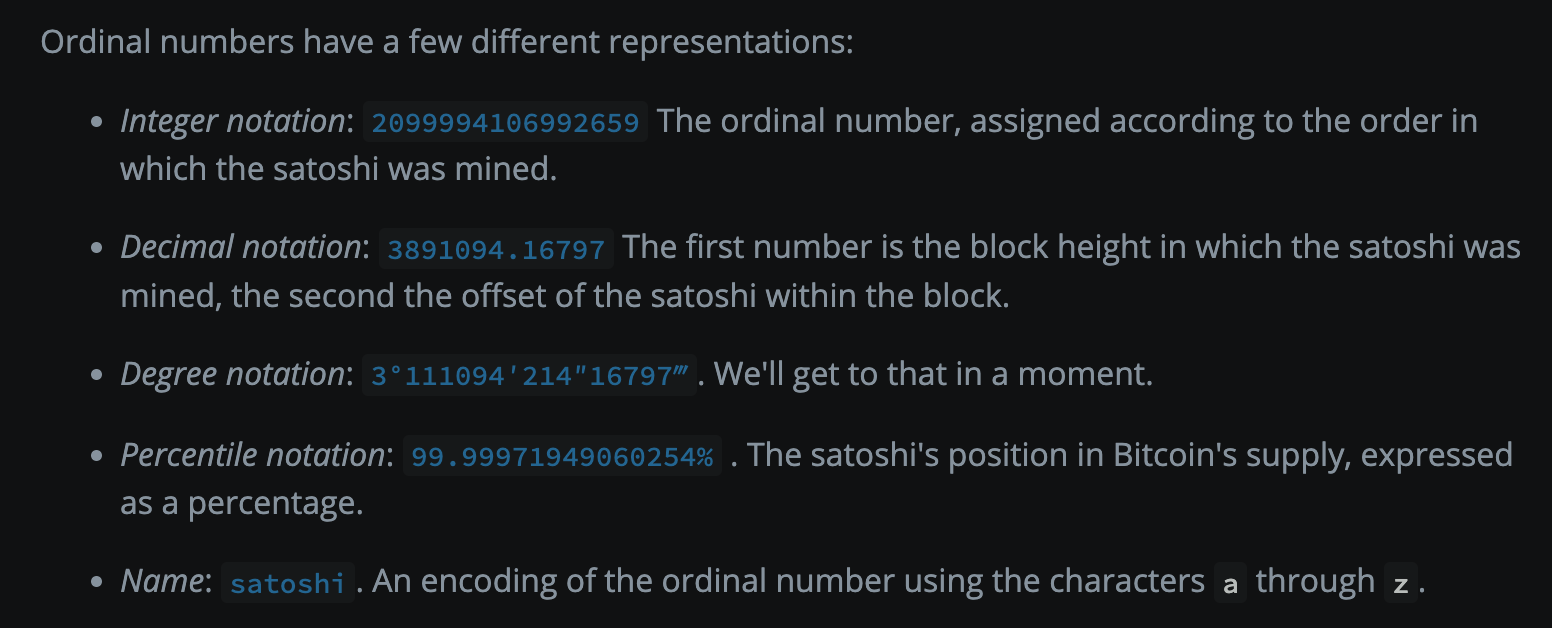
sats有了统一的序号之后,就可以考虑铭刻了(inscription)了。我们在上文中提到,可以在见证数据区域4M大小的空间上传任意数据类型的文件,不管是文本,还是图片和视频,上传之后,文件会自动转为16进制存放在的taproot脚本区。所以是,1个UTXO,对应1个Taproot脚本区,而这1个UTXO会同时包含很多sats(整体是一个sats序列集合,为了防止粉尘攻击,限制单个 UTXO 中的比特币数量不可少于 546 聪。)。Ordinal协议为了方便记录,人为地规定“使用这个序列集合的第一个sat编号来代表绑定关系”(白皮书原话是第一个output的第一个聪的编号),比如包含(17-19)号sats的UTXO就直接用17号来代替这个集合和铭刻内容绑定。
Ordinal资产的铸造和转移
Ordinal NFT很显然就是把各种文件上传到隔离见证区的脚本中并与之绑定一个sats序列集合,从而实现了在BTC链上发行NFT资产。但是这里还有一个问题,隔离见证区的脚本即包含input的解锁脚本,又包含output的锁定脚本,那么内容是放在哪个脚本中呢?正确的答案是两者都有。这里不得不提到区块链技术中的commit-reveal机制。
区块链中的Commit-Reveal机制是一种用于确保信息公平和透明处理的协议。这个机制通常用在需要提交隐藏信息(如投票或竞标),然后在以后的某个时间点揭示这些信息的场景中。Commit-Reveal机制分为两个阶段:提交(Commit)阶段和揭示(Reveal)阶段。
1. 提交(Commit)阶段:在这个阶段,用户提交他们的信息(如投票选择或竞标价格),但这个信息是加密的。通常,用户会生成这个信息的哈希值(即信息的加密摘要),然后将这个哈希值发送到区块链上。由于哈希函数的特性,它们可以生成一个独特的输出(哈希值),这个输出对于原始信息来说是不可逆的。这意味着无法从哈希值推断出原始信息。这个过程确保了信息在提交时的保密性。
2. 揭示(Reveal)阶段:在一个预定的以后时间,用户必须揭示他们的原始信息,并证明它与之前提交的哈希值相匹配。这通常是通过提交原始信息以及用于生成哈希值的任何附加数据(如随机数或“盐”)来完成的。网络然后验证这个原始信息的哈希值是否与之前提交的哈希值相同。如果匹配,则原始信息被接受为有效。
我们前面讲过,铭刻的内容是需要和UTXO包含的sats序列集合绑定一起,UTXO在区块中是一个output,所以必须附着在output的锁定脚本中。但是BTC的全节点需要在本地维护和传输全网络所有的UTXO集合。想象一下,要是有1万个4M的视频文件直接上传到1万个UTXO的锁定脚本,那所有的全节点需要有超高的存储空间和超快的网速,可以说整个链直接就崩了。因此,唯一的解决方法是把内容放到input中的解锁脚本,然后再让这个内容“指向”到另一个output。
所以说Ordinal资产的铸造是需要分为两步(钱包是把这两步进行合并处理了,在构造交易时,同时构造commit-reveal这个父子交易,用户体验上会感觉只有一个步骤并且节省了gas费)。
在铸造阶段,用户首先需要上传某个文件的哈希值到commit交易中(自己A地址给自己B地址转账)的UTXO中的锁定脚本,因为是哈希值,所以不占用过多全节点的UTXO数据库空间。其次,用户再构造一个新的交易(自己B地址给自己A地址转账),称之为reveal交易,此时的input需要使用上一步commit交易中含有文件哈希值的那个UTXO,并且该input的解锁脚本必须包含原始铭刻文件。用白皮书中的原话描述,就是“首先,在commit中,创建一个提交到包含铭文内容的脚本的taproot 输出。 其次,在reveal交易中,使用commit交易产生的输出,来显示链上的铭文内容。”
在转移阶段,Ordinal NFT和 BRC20稍有不同,Ordinal NFT因为是整体转移,只需要把绑定某个UTXO的NFT直接转给接收者即可,类似于普通的BTC转账。但BRC20因为牵扯到自定义数额转账,同样分为两步,第一步叫铭刻“交易”(Inscribe "TRANSFER"),第二步叫转账“交易”(Transfer "TRANSFER"),第一步的铭刻交易实际类似于一个Ordinal NFT的铸造过程,暗含了commit-reveral 父子交易对,第二步转账交易类似于一个普通的Ordinal NFT的转账,把绑定某个UTXO的BRC20资产直接转给接收者。有的钱包会把这三个交易(父子孙三代交易)同时构建,从而节省时间和gas。

总结来说,commit交易用来把铭刻内容(原始内容的哈希值)和带序号的sats(UTXO)绑定,reveal交易用来把内容显示出来(原始内容)。这个父子交易对共同完成了对于NFT的铸造。
P2TR与一个例子
上面关于铸造的技术讨论还没完结,因为有人会好奇,reveal交易到底是如何验证commit交易中的铭文信息呢?为啥构造交易的时候需要自己的AB两个地址互相转账呢?打铭文的时候也没看到需要准备两个钱包啊。这里就需要讲到Taproot的重大升级之一P2TR了。
P2TR (Pay-to-Taproot)是由Taproot升级引入的一种新类型的比特币交易。P2TR交易通过允许用户使用单一公钥或更复杂的脚本(如多重签名钱包或智能合约)来花费比特币,实现了更高的隐私和灵活性。这是通过使用Merkleized Abstract Syntax Trees(MAST)和Schnorr签名来实现的,这些技术使得可以在单个交易中有效地编码多种花费条件。
- 创建花费条件
要创建一个P2TR交易,用户首先定义一个花费条件,例如单一公钥或更复杂的脚本,指定了花费比特币的要求(例如,多重签名钱包或智能合约)。
- 生成Taproot输出
然后,用户生成一个Taproot输出,其中包括一个单一公钥(公钥代表花费条件)。这个公钥是从用户的公钥和脚本的哈希的组合中派生出来的,使用一种称为“tweaking”的过程。这确保了输出看起来像一个标准的公钥,使其在区块链上与其他交易难以区分。
- 花费比特币
当用户想要花费比特币时,他们可以使用他们的单一公钥(如果花费条件被满足),或者透露原始脚本并提供必要的签名或数据以满足花费条件。这是通过使用Tapscript来完成的,它允许更高效和灵活地执行花费条件。
- 验证交易
矿工和节点随后通过检查所提供的Schnorr签名和数据与花费条件进行验证交易。如果条件被满足,交易被视为有效,比特币可以被花费。
- 增强的隐私和灵活性
因为P2TR交易只在花费比特币时透露必要的花费条件,所以它们保持了高水平的隐私。此外,使用MAST和Schnorr签名使得能够高效地编码多个花费条件,允许更复杂和灵活的交易,而不会增加交易的总体大小。
以上就是commit-reveal机制在P2TR中的应用方式,我们以一个实际案例来做说明。
使用区块链浏览器 我们来研究一个Ordinal 图片NFT的铸造过程,包括了之前的commit-reveal两个阶段。
首先,我们看到commit交易的Hash ID是(2ddf90ddf7c929c8038888fc2b7591fb999c3ba3c3c7b49d54d01f8db4af585c)。可以注意到,这笔交易的输出不包含铭文数据(实际上放的是16机制图片文件的哈希值),网页中也没有相关的铭文信息。这个输出的(bc1p4mtc…..)地址其实是通过“tweaking”过程产生的临时地址(代表了脚本解锁条件的公钥),和taproot主地址(bc1pg2mp…)共享一个私钥。此交易中的第二个UTXO属于返还的“找零”操作。如此就实现了铭文内容与第一个UTXO包含的sats的绑定。
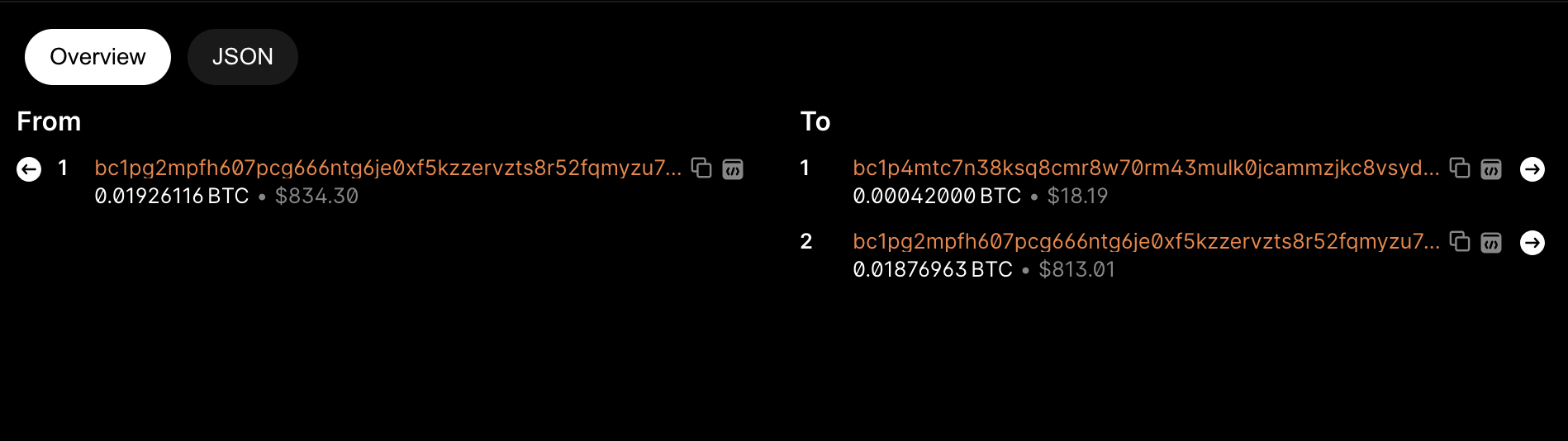
接着,我们查看reveal交易的记录,其Hash ID是(e7454db518ca3910d2f17f41c7b215d6cba00f29bd186ae77d4fcd7f0ba7c0e1)。在这里,我们可以看到Ordinals inscription 的信息。这笔交易的input地址正是前一个交易产生的临时输出地址(bc1p4mtc…..),input的解锁脚本则包含了原始图片的16进制文件,而输出的0.00000546BTC(546聪)则是将这个NFT发送到自己的taproot主地址(bc1pg2mp…)。基于First in First Out原则以及“绑定的是第一个output的第一个聪的编号”,虽然前后两个UTXO包含的sats的数量有变化,但是绑定的sat序号不变。所以,我们可以在(sat 1893640468329373)中找到这个铭文所在的聪。
()
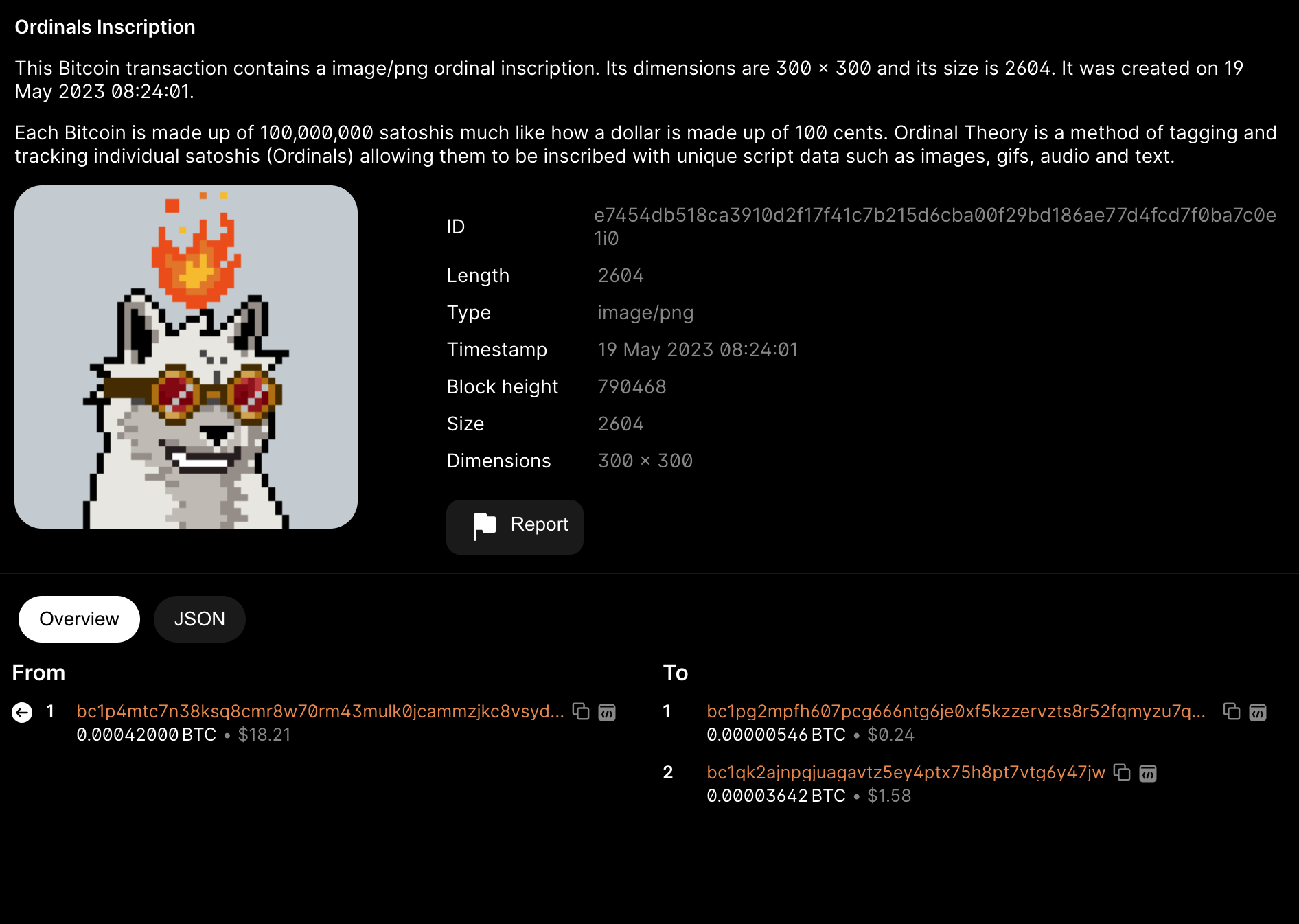
这两个交易(属于父子交易)在铸造时会同时由钱包提交给内存池,所以只需要花费一笔gas,也很大几率是进入到同一个区块中被矿工记录并广播(以上例子中的两个交易正是同时存在于区块790468中。)。矿工和节点随后通过检查reveal交易中的input所提供的Schnorr签名以及16进制图片的哈希值与commit交易中的output锁定脚本中的16进制图片哈希值进行验证。如果两者相同,交易被视为有效,这个比特币的UTXO可以被花费,那么这两个交易自然就被永久记录在BTC的区块链数据库中,NFT的图片也自然被保存下来并显示出来。如果两个哈希值不同,两个交易会被取消,铭刻失败。
BRC20协议与索引器
对于Ordinal协议,我们铭刻一段文本,它就是文字NFT(对应以太坊上的Loot),铭刻一张图片,它就是图片NFT(对应于以太坊上的PFP),铭刻一段音乐,它就是音频NFT。那如果我们铭刻一段代码,并且这段代码是一段“发行FT同质化代币”的代码呢?
BRC20正是通过利用 Ordinal 协议将inscriptions(铭文)设置为 JSON 数据格式来部署、铸造和转移 Token,JSON 包含一些代码片段,描述 Token 的各种属性,例如其供应量、最大铸造单位和唯一代码。我们在上一篇文章中已经讲过,BRC20代币的本质是半同质化代币SFT,也就是说,在某些情况它可以当做NFT交易,某些情况可以当做FT交易,这种对“不同情况”的控制是如何办到的呢?答案是索引器。
索引器其实是一个记账人,用来把接收到的信息分门别类的记录在数据库里。在Ordinal协议中,索引器通过对input和output的追踪,来确定排序好的sats在不同地址中的变化。在BRC-20协议里,索引器多了一个功能:记录铭文中代币余额在不同地址的变化。
所以我们可以从记账人的视角来看到不同的代币存在形式:BRC20协议代币其实存在于一个三重数据库中。第一重Layer1,记账人是BTC矿工,数据库类型是“链式数据库”,产生的BTC是FT资产。第二重layer2,记账人是Ordinal索引器,数据库类型是“关系型数据库”,产生的带序号的sats是NFT资产。第三重layer3,记账人是BRC20索引器,数据库类型是“关系型数据库”,产生的BRC20资产是FT资产。当我们把BRC20按照“张”来算的时候,站的角度是ordinal索引器(由该索引器记录),它自然是NFT;当我们把BRC20按照分拆好的“个”来思考的时候(尤其是充值到中心化交易所之后),站的角度是BRC20索引器(由该索引器记录或者是中心化交易所的服务器记录),它自然是FT。由此我们可以得到一个结论,半同质化代币SFT的存在是因为有不同层级的记账人导致的。
区块链不就是一个分布式数据库嘛,所以才有了矿工这个记账人群体来共同维护这个“链式数据库”(因为只有链式数据库才能做到真正的去中心化)。但兜兜转转,我们还是回到了中心化的“关系型数据库”的老路。这也是为何前段时间Ordinal协议发起人,BRC20协议发起人,unisat钱包为了索引器是否要升级炒的不可开交的本质原因–记账人意见不一致啦。
但是行业经过了十几年的发展,还是积攒了不少“去中心化”的经验,索引器可不可以用“链式数据库”替代关系型数据库?能不能采用欺诈证明或者ZKP来保证安全和去中心化?比特币生态的DA需求会不会溢出到其他的DA从而促进多链生态繁荣和融合?我似乎看到了更多的可能性。
本文由 @hicaptainz 原创
参考资料


.jpg){kind=link}