
用多因子模型构建强大的加密资产投资组合:因子正交化篇
通过因子正交化,重新调整原始因子的方向,使他们相互正交([fᵢ→,fⱼ→]=0,即两个向量相互垂直),本质是对原始因子在坐标轴上的旋转。这种旋转不改变因子之间的线性关系也不改变原本蕴含的信息,并且新因子之间的相关性为零(内积为零等价于相关性为零),因子对于收益的解释度保持不变。
一、因子正交化的数学推导
从多因子截面回归角度,建立因子正交化体系。
每个截面上可以获得全市场token在各个因子上的取值,N代表截面上全市场token数量,K表示因子的数量,fᵏ=[f₁ᵏ,f₂ᵏ,…,f៷ᵏ]′表示全市场token在第k个因子上的取值,并且已对每个因子进行了z-score归一化处理,即 fˉᵏ=0,∣∣fᵏ∣∣=1。
Fₙ×ₖ=[f¹,f²,…,fᵏ]为截面上K个线性独立的因子列向量组成的矩阵,假设以上因子线性无关(相关性不为100%或-100%,正交化处理的理论基础)。
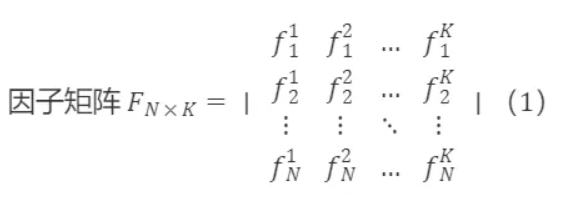
通过对Fₘₙ线性变换,得到一个新的因子正交矩阵F′ₘₙ=[f₁ᵏ,f₂ᵏ,…,fₙᵏ]′ ,新矩阵的列向量相互正交,即任意两个新因子向量内积为零,∀ᵢ,ⱼ,ᵢ≠ⱼ,[(f~ⁱ)’f~ʲ]=0。
定义一个从 Fₙ×ₖ旋转到F~ₙ×ₖ的过渡矩阵 Sₖ×ₖ
F~ₙ×ₖ=Fₙ×ₖ⋅Sₖ×ₖ(2)
1.1 过度矩阵Sₖ×ₖ
以下开始求解过渡矩阵Sₖₖ,首先计算Fₙₖ的协方差矩阵∑ₖₖ,则 Fₙₖ 的重叠矩阵Mₖₖ=(N−1)∑ₖₖ,即
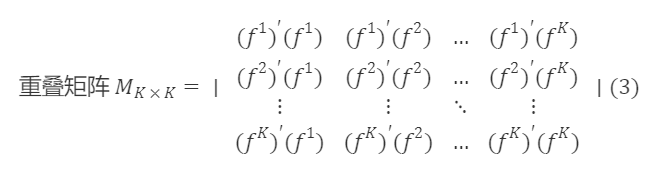
旋转后的F~ₙ×ₖ是正交矩阵,根据正交矩阵的性质 AAᐪ=I,则有
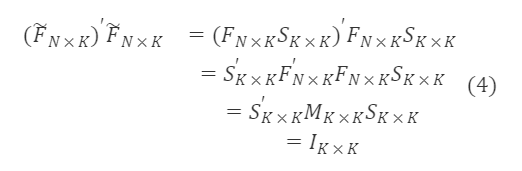
所以,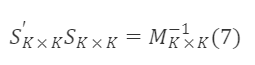
满足该条件的 Sₖₖ 即为一个符合条件的过渡矩阵。上面公式的通解为
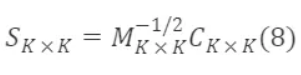
其中,Cₖ×ₖ 为任意正交矩阵
1.2对称矩阵Mₖ×ₖ⁻¹/²
下面开始求解 M∗ₖ×ₖ⁻¹/²,因为 M∗ₖ×ₖ 是对称矩阵,因此一定存在一个正定矩阵 Uₖ×ₖ 满足:
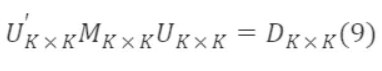
其中,

U∗K×K,D∗K×K 分别为 M∗K×K 的特征向量矩阵和特征根对角矩阵,并且 U∗K×K′=Uₖ×ₖ⁻¹,∀ₖ,λₖ>0。 由公式(13)可得
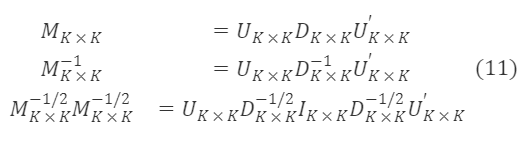
由于 M∗ₖ×ₖ⁻¹/² 是对称矩阵,且 U∗ₖ×ₖU∗ₖ×ₖ′=I∗ₖ×ₖ,可基于上式得到 M∗ₖ×ₖ⁻¹/² 的一个特解为:
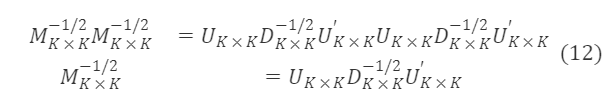
其中
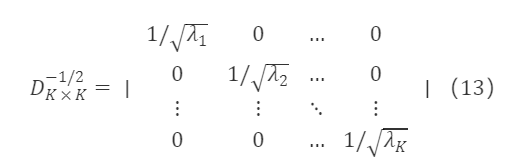
将 M∗ₖ×ₖ⁻¹/² 的解带入公式(6)可求的过渡矩阵:
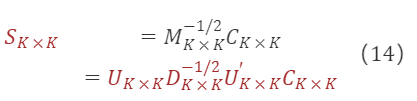
其中,Cₖ×ₖ 为任意正交矩阵。
根据公式(12),任何一种因子正交都可以转化为选择不同的正交矩阵 Cₖ×ₖ 对原始因子进行旋转。
1.3消除共线性主要用到3种正交方法
1.3.1 施密特正交
故,S∗K×K 为上三角矩阵,C∗K×K=U∗K×KD∗K×ₖK⁻¹/²U∗K×K′S∗K×K
1.3.2 规范正交
故,Sₖ×ₖ=Uₖ×ₖDₖ×ₖ⁻¹/² ,Cₖ×ₖ=Uₖ×ₖ
1.3.3 对称正交
故,Sₖ×ₖ=Uₖ×ₖDₖ×ₖ⁻¹/²U′ₖ×ₖ,Cₖ×ₖ=Iₖ×ₖ
二、三种正交方法的具体实现
1.施密特正交
有一组线性无关的因子列向量 f¹,f²,…,fᵏ,可以逐步的构造出一组正交的向量组 f~¹,f~²,…,f~ᵏ,正交后的向量为:
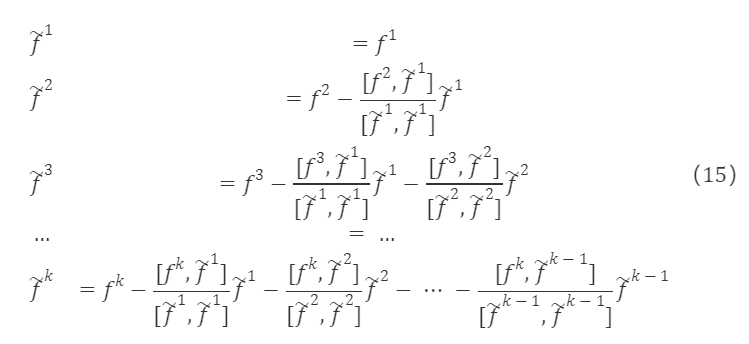
并对 f~¹,f~²,…,f~ᵏ 进行单位化后:
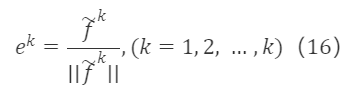
经过以上处理,得到一组标准正交基。由于 e¹,e²,…,eᵏ 与 f¹,f²,…,fᵏ 等价,二者可以相互线性表示,即 eᵏ是 f¹,f²,…,fᵏ 的线性组合,有 eᵏ=βᵏ₁f¹+βᵏ₂f²+…+βᵏₖfᵏ,因此对应于原矩阵 F∗K×K的过渡矩阵S∗K×K 为一个上三角矩阵,形如:
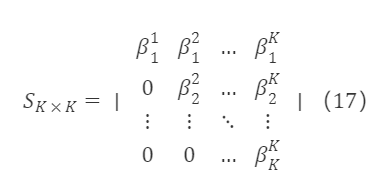
其中
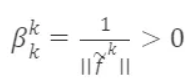
基于公式(17),施密特正交选取的任意正交矩阵为:
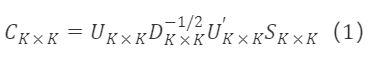
施密特正交是一种顺序正交方法,因此需要确定因子正交的顺序,常见的正交顺序有固定顺序(不同截面上取同样的正交次序),以及动态顺序(在每个截面上根据一定规则确定其正交次序)。施密特正交法的优点是按同样顺序正交的因子有显式的对应关系,但是正交顺序没有统一的选择标准,正交后的表现可能受到正交顺序标准和窗口期参数的影响。
# 施密特正交化
from sympy.matrices import Matrix, GramSchmidt
Schmidt = GramSchmidt(f.apply(lambda x: Matrix(x),axis=0),orthonormal=True)
f_Schmidt = pd.DataFrame(index=f.index,columns=f.columns)
for i in range(3):
f_Schmidt.iloc[:,i]=np.array(Schmidt[i])
res = f_Schmidt.astype(float)
2.规范正交
选取正交矩阵 Cₖ×ₖ=Uₖ×ₖ,则过渡矩阵为:
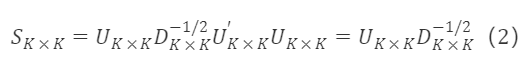
其中 U*K×K为特征向量矩阵,用于对因子旋转,D∗K×K⁻¹/² 为对角矩阵,用于对旋转后因子的缩放。此处的旋转与不做降维的PCA一致。
# 规范正交
def Canonical(self):
overlapping_matrix = (time_tag_data.shape[1] – 1) * np.cov(time_tag_data.astype(float))
# 获取特征值和特征向量
eigenvalue, eigenvector = np.linalg.eig(overlapping_matrix)
# 转换为np中的矩阵
eigenvector = np.mat(eigenvector)
transition_matrix = np.dot(eigenvector, np.mat(np.diag(eigenvalue ** (-0.5))))
orthogonalization = np.dot(time_tag_data.T.values, transition_matrix)
orthogonalization_df = pd.DataFrame(orthogonalization.T,index = pd.MultiIndex.from_product([time_tag_data.index, [time_tag]]),columns=time_tag_data.columns)
self.factor_orthogonalization_data = self.factor_orthogonalization_data.append(orthogonalization_df)
3.对称正交
施密特正交由于在过去若干个截面上都取同样的因子正交顺序,因此正交后的因子和原始因子有显式的对应关系,而规范正交在每个截面上选取的主成分方向可能不一致,导致正交前后的因子没有稳定的对应关系。由此可见,正交后组合的效果,很大一部分取决于正交前后因子是否有稳定的对应关系。
对称正交尽可能的减少对原始因子矩阵的修改而得到一组正交基。这样能够最大程度地保持正交后因子和原因子的相似性。并且避免像施密特正交法中偏向正交顺序中靠前的因子。
选取正交矩阵 Cₖ×ₖ=Iₖ×ₖ,则过渡矩阵为:
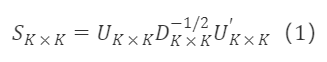
对称正交的性质:
- 与施密特正交相比,对称正交不需要提供正交次序,对每个因子是平等看待的
- 在所有正交过渡矩阵中,对称正交后的矩阵和原始矩阵的相似性最大,即正交前后矩阵的距离最小。
# 对称正交
def Symmetry(factors):
col_name = factors.columns
D, U = np.linalg.eig(np.dot(factors.T, factors))
U = np.mat(U)
d = np.diag(D**(-0.5))
S = U*d*U.T
#F_hat = np.dot(factors, S)
F_hat = np.mat(factors)*S
factors_orthogonal = pd.DataFrame(F_hat, columns=col_name, index=factors.index)
return factors_orthogonal
res = Symmetry(f)



.jpg){kind=link}