
为什么说Arweave 2.6更符合中本聪的愿景?

作者: Arweave Oasis
我们在此前文章 《》中已经了解到 在过去五年中的技术迭代历程,并在文章中承诺会再就 2.6 版本进行一次比较全面的解析。本文就来兑现这个承诺,带大家来了解一下 Arweave 2.6 版本的共识机制设计细节。
写在前面
大概还有一个月, 就要开始下一轮减半。但笔者认为中本聪的愿景—— 人人都可以用 CPU 参与的共识,始终没有得到实现。这一点,Arweave 的机制迭代可能更加忠实于中本聪原初的愿景,而 2.6 版本让 Arweave 网络开始真正地符合了中本聪的预期。它较于先前的版本,做大幅度改进,就为了实现:
限制硬件加速,通用级 CPU + 机械硬盘就可以参与系统的共识维护,从而降低存储成本;
将共识成本尽可能引向有效的数据存储,而不是高耗能的哈希军备竞赛;
激励矿工建立自己的完整 Arweave 数据集副本,允许数据更快地路由和更加分布式地存储。
共识机制
基于以上目标,2.6 版本的机制大致如下:
在原本的 SPoRA 机制中新增一个组件称为哈希链(Hash Chain),它就是之前提及的加密算法时钟,每秒会生成一个 SHA-256 的挖矿哈希(Mining Hash)。
矿工在自己存储的数据分区中选择一个分区的索引,将其与挖矿哈希,挖矿地址一起作为挖矿输入信息来开始挖矿。
在矿工选择的分区中生成一个回溯范围 1,并在编织网络中的随机位置再生成一个回溯范围 2。
依次使用回溯范围 1 内的回溯数据块(Chunk)来计算,尝试是否是区块解决方案。如果计算结果大于当前网络难度,矿工获得出块权;如果没有成功,就计算回溯范围中的下一个回溯块。
范围 2 中的回溯数据块也可能被计算验证,但那里的解决方案需要范围 1 的哈希。
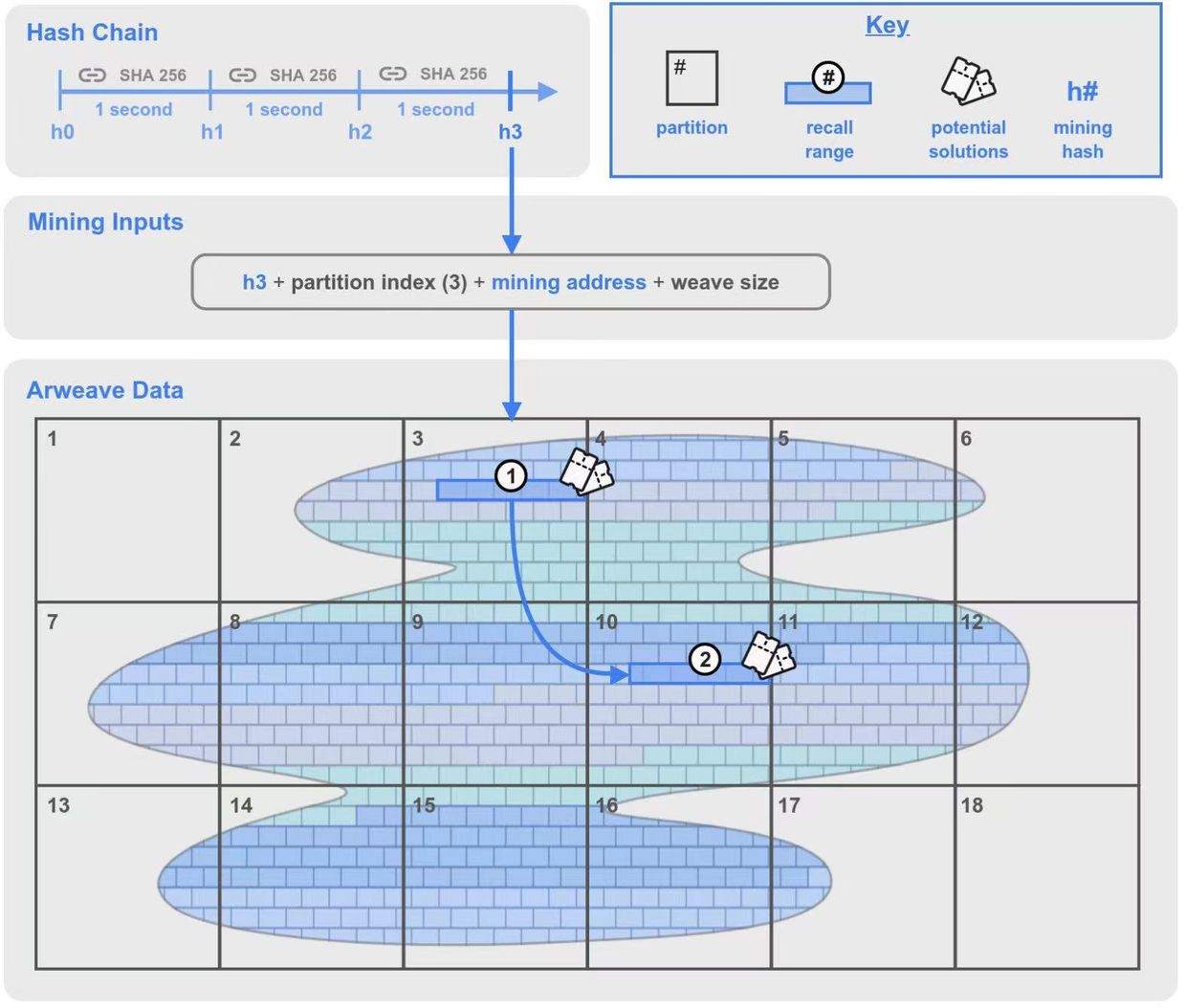
图 1: 2.6 版本的共识机制示意图
来认识一下在此机制中出现的各种名词概念:
Arweave 数据(Arweave Data):又称“编织网络”。网络中的所有数据都被分割成一个一个的数据块,英文名称 Chunk(上图中像“砖墙”一样的一个个块就是 chunk)。这些块可以在 Arweave 网络中均匀分布,并通过默克尔树的方式来为每一个数据块建立寻址方案(也称为 Global Offset 全局偏移量),以此来识别编织网络中任何位置的数据块。
数据块(Chunk):每个数据块的大小通常为 256 KB。矿工要赢得出块权就必须对相应数据块进行打包与哈希处理,并在 SPoRA 挖矿过程中证明他们存储了数据副本。
分区(Partition):「分区」是在 2.6 版本中新增的概念。每 3.6TB 为一个分区。分区从编织网络的开始处(索引为 0)一直编号到覆盖整个编织网络的分区数量。
回溯范围(Recall Range):回溯范围也是 2.6 版本中的新增概念。它是编织网络中从特定偏移量开始、长度为 100MB 的一系列连续的数据块(Chunk)。按 256 KB 一个数据块来算,在一个回溯范围中包括了 400 个数据块。该机制中,会有两个回溯范围,下文会作详细解释。
潜在解决方案(Potential Solutions):回溯范围内的每个 256KB 数据块都将是获得出块权的潜在解决方案。作为挖矿过程的一部分,每个数据块都会被哈希处理,来测试它是否满足网络的难度要求。如果满足,矿工就赢得了出块权并获得挖矿奖励。如果不满足,矿工将继续尝试回溯范围内的下一个 256KB 块。
哈希链(Hash Chain):哈希链是 2.6 版本的关键更新,它在之前的 SPoRA 上添加的一个加密时钟,起到了限制最大哈希量的限速作用。哈希链通过使用 SHA-256 函数对一段数据进行连续次哈希而生成的。这个过程不能并行计算(消费级 CPU 就可以轻松做到),哈希链通过进行一定数量的连续哈希处理来达成延迟 1 秒的效果。
挖掘哈希(Mining Hash):在进行足够数量的连续哈希之后(即经过了 1 秒的延迟),哈希链产出一个被认为对挖矿有效的哈希值。值得注意的是,挖矿哈希在所有矿工之间是一致的,并且所有矿工都可以验证。
介绍完所有必要的名词概念后,我们可以通过如何获得最佳策略来一起更好地理解 2.6 版本是如何运作的。
最佳策略
Arweave 的总目标之前已经多次介绍,就是最大化网络上存储数据副本的数量。但存什么?怎么存?其中也有不少要求与门道。这里我们来讨论如何采取一个最佳策略。
Replicas 与 Copies
自 2.6 版本之后,笔者在各种技术资料里就频繁看到两个词,Replicas 与 Copies。这两个概念翻译成中文都可以是副本的意思,但其实它们之间有着非常大的差别,这也为我在理解机制的时候造成了不小的障碍。为了便于理解,我倾向于将 Replicas 翻译成「副本」,将 Copies 翻译成「备份」。
Copies 备份是指单纯地对数据进行复制,相同数据的备份之间没有差异。
Replicas 副本的意思讲究其唯一性,是在对数据进行了一次唯一性处理后再存储的行为。Arweave 网络鼓励的是对副本的存储,而不是单纯的备份存储。
Note: 在 2.7 版本中共识机制变成了 SPoRes,即为 Succinct Proofs of Replications 简洁的复制证明,就是以副本存储展开的,我将在未来再行解读。
打包唯一副本(Packing unique replicas)
唯一副本在 Arweave 机制中非常重要,矿工想要获得出块权,就必须将所有数据都以特定的格式打包处理,以形成属于自己的唯一副本,这是先决条件。
如果你想要跑一个新的节点,想着直接拷贝其它矿工已经打过包的数据是不行的。你首先需要将 Arweave 编织网络中的原始数据下载同步下来(当然你不想全部下载,只下载部分也可以,还可以设置自己的数据政策,过滤掉有风险的数据),然后通过 RandomX 函数来打包这些原始数据的每一个数据块,让其成为潜在的挖矿解决方案。
打包过程包括提供一个 Packing Key 打包密钥给 RandomX 函数,让它通过多次运算而生成的结果用于打包原始数据块。解压已打包数据块的过程也是一样,提供打包密钥,用通过多次运算生成的结果去解压已打包数据块。
在 2.5 版本中,Packing Key 备份是由 chunk_offset(数据块的偏移量,也可以理解成数据块的位置参数)和 tx_root(交易根)关联后的 SHA256 哈希。这保证了每次挖掘矿解决方案都来自于特定区块中数据块的唯一副本。如果一个数据块在破坏网络中不同位置存在多个备份,每个备份都需要单独备份成唯一副本。
在 2.6 版本中,这个备份密钥被扩展为 chunk_offset、tx_root 和 miner_address(矿工地址)关联后的 SHA256 哈希。这意味着每个副本也对每个挖矿地址都是唯一的。
存储完整副本的优势
算法建议矿工去构建一个唯一的完整副本,而不是被多次复制的部分副本,这使得网络中数据均匀分布。
这部分怎么理解呢?我们通过下面两张图的对比来理解。
首先让我们先假设整个 Arweave 断裂网络一共产生了 16 个数据分区。
第一种情况:
- 矿工鲍勃嫌下载数据太费时,所以只下载了破坏网络的前 4 个分区的数据。
- 为了能够最大化这 4 个分区的挖矿副本,鲍勃灵机一动,把这 4 个分区的数据复制了 4 份,并分别用不同的 4 个挖矿地址将它们组成 4 个唯一副本资源来填充自己的存储空间,所以现在在 Bob 的存储空间中有 16 个分区。这样没有问题,符合唯一副本的规则。
- 接下来,Bob 可以在每秒获得挖矿哈希(Mining Hash)的时候,为分区每个生成一个回溯范围物质其中的数据块进行侵犯测试。这使得 Bob 在一秒内获得 400* 16=6400 次潜在挖矿解决方案。
- 但鲍勃也为他的小聪明代价第二,因为他必须损失了一个回溯范围的挖矿机会,看到这些的那些「小问号」了吗?它们代表了相关的第二次一个回溯范围在 Bob 的硬盘中是找不到的,因为他们标志着 Bob 没有存储的数据分区中。当然运气好,也有比较低的指示灯象征着 Bob 存储的 4 个分区中,这一点也就 25%,即 1600 个潜在解决方案。
- 所以这个策略让 Bob 每秒有 6400+1600=8000 个潜在解决方案。
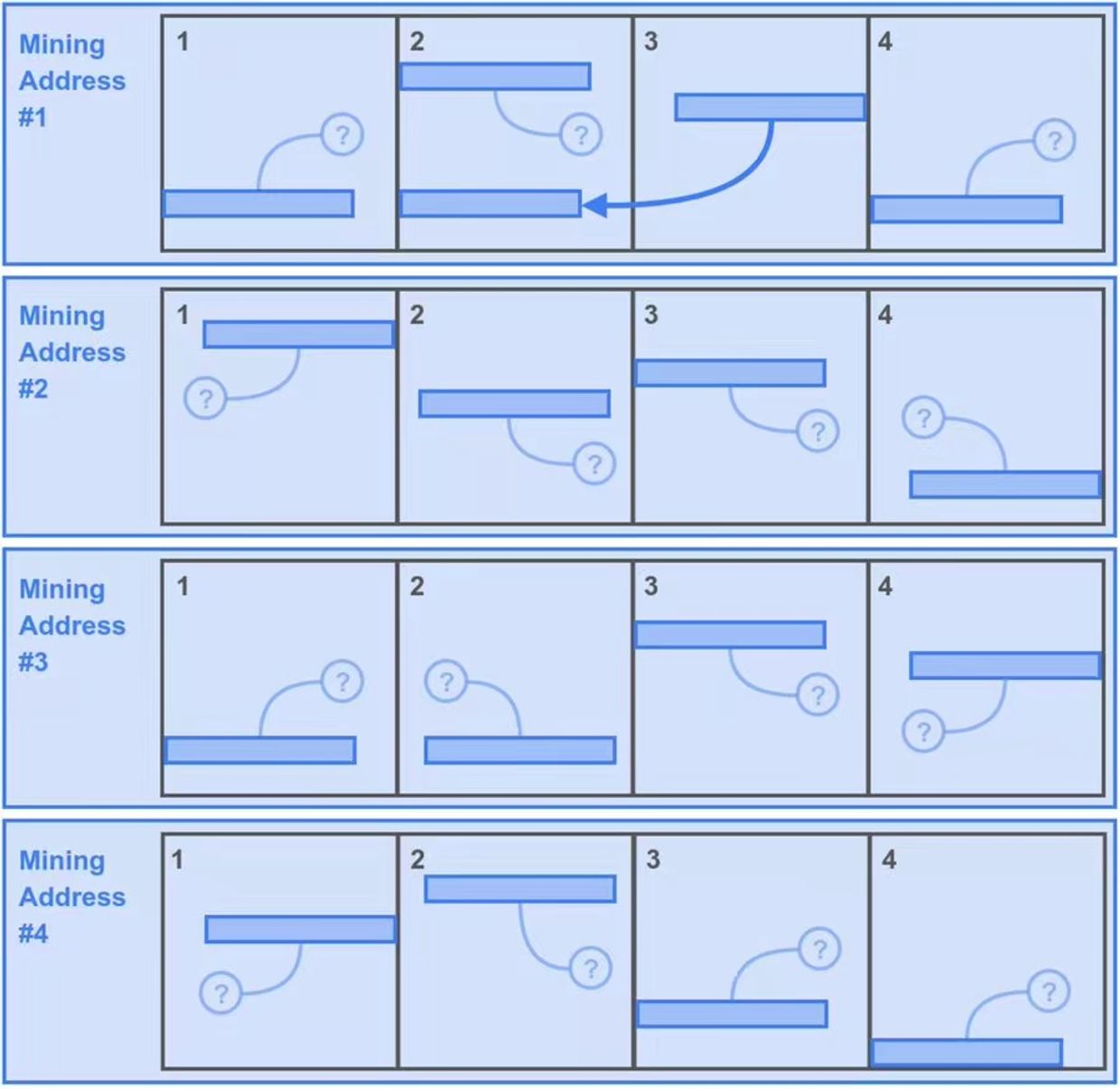
图 2:第一种情况,Bob 的「小聪明」策略
第二种情况:
那我们再看看第二个情况。由于两个回溯范围的机制安排,一个更优的策略就是存储问题多的唯一副本。如图 3 所示。
- 矿工 Alice 就不像 Bob 那样「聪明伶俐」,她本分地下载了所有 16 个分区的分区数据,并且只用一个挖矿地址将 16 个备份组成唯一副本。
- 因为 Alice 也是 16 个分区,所以第一个回溯范围的总潜在解决方案与 Bob 一致,也是 6400 个。
- 但在这种情况下,Alice 获得了所有第二个回溯范围潜在解决方案。那就是额外的 6400 个。
- 所以这让 Alice 策略每秒有 6400+6400=12800 个潜在解决方案。优势不言而喻。
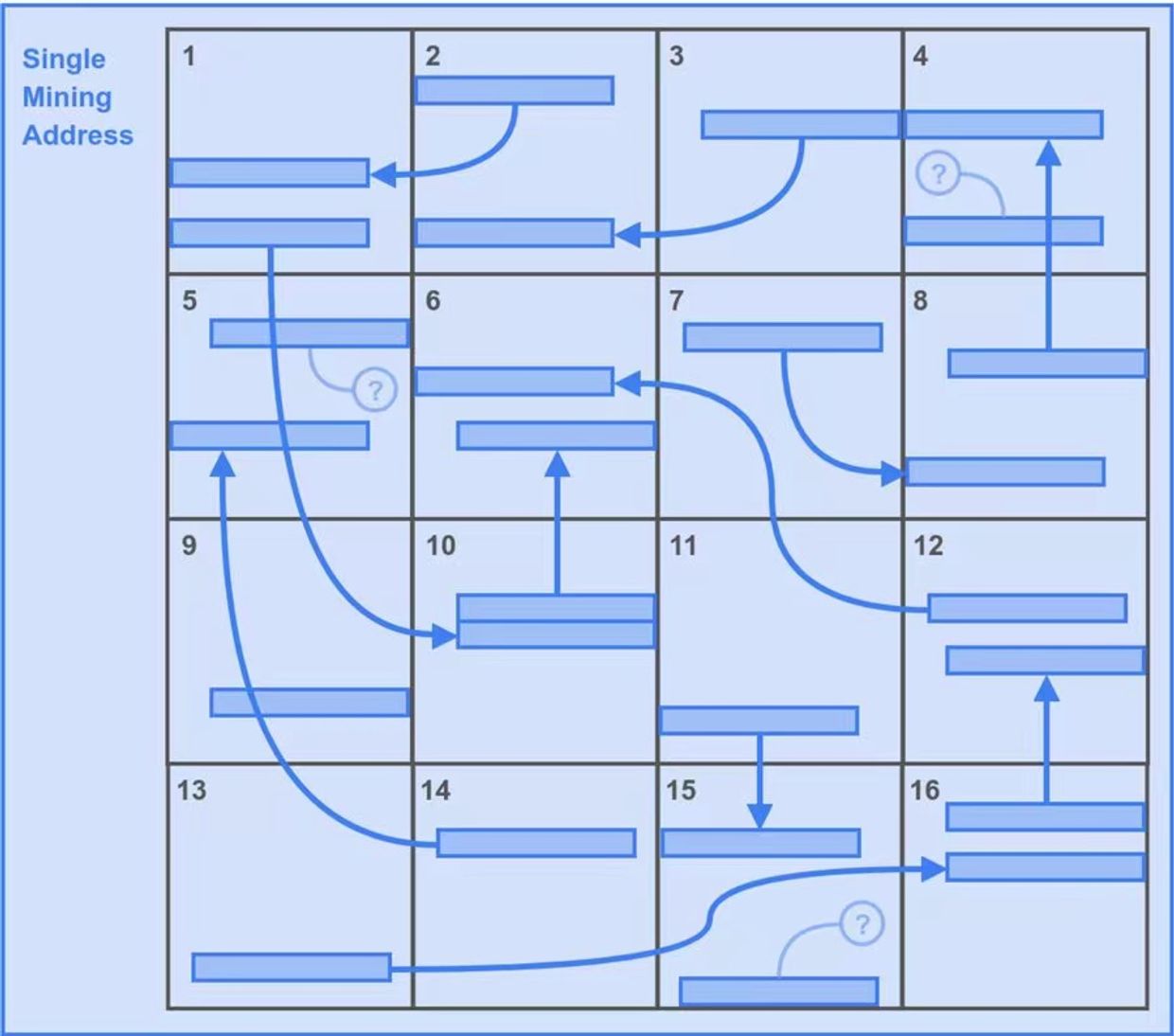
图 3:Alice 的策略,显然有更大的优势
回溯范围的作用
也许你会奇怪,在 2.5 版本之前都是随机地通过函数哈希出单个回溯块的偏移量再次让矿工查找并给出存储证明,为什么到了 2.6 会是哈希出一个回溯范围呢?
原因其实很好理解,回溯范围是由连续的数据块组成的,这种结构不为别的,其目的就是让机械硬盘(HDD)的读取头的移动量最小化。这种方式带来的物理上的优化使 HDD 的读取性能可以与更昂贵的 SSD 硬盘(SSD)放在一起。这就像给 SSD 绑住了一只手与一只脚,当然能够每秒传输四个回溯范围拥有昂贵的 SSD,还是有一点点的速度优势。但相比更便宜的 HDD,其计数将是促使矿工选择的关键指标。
哈希链的验证
现在我们来讨论下一个新区块的验证问题。
要接受一个新区块,验证者需要对区块生产者同步过来的新块作验证,方法是可以用自己生成的挖矿哈希来验证新区块的挖矿哈希。
如果验证者不在哈希链的当前头部,则每个挖矿哈希包括 25 个 40 毫秒的检查点。这些检查点是连续哈希 40 毫秒的结果,它们组合到一起便代表了来自前一个挖矿的哈希开始的一秒间隔。
验证者在将新收到的区块传播给其他节点之前,将在 40 毫秒内快速完成验证前 25 个检查点,如果验证成功,则引发传播区块,并继续完成剩余检查点的验证。完整的检查点是通过全部验证剩余检查点而完成的。前 25 个检查点之后是 500 个验证的检查点,然后是 500 个验证的检查点,每个小组后续的 500 个检查点点的间隔加倍。
哈希链在产生挖矿哈希时,必须按顺序单线进行。但验证者验证检查点时可以进行哈希验证,这可以让验证区块的时间变得更短,提高效率。
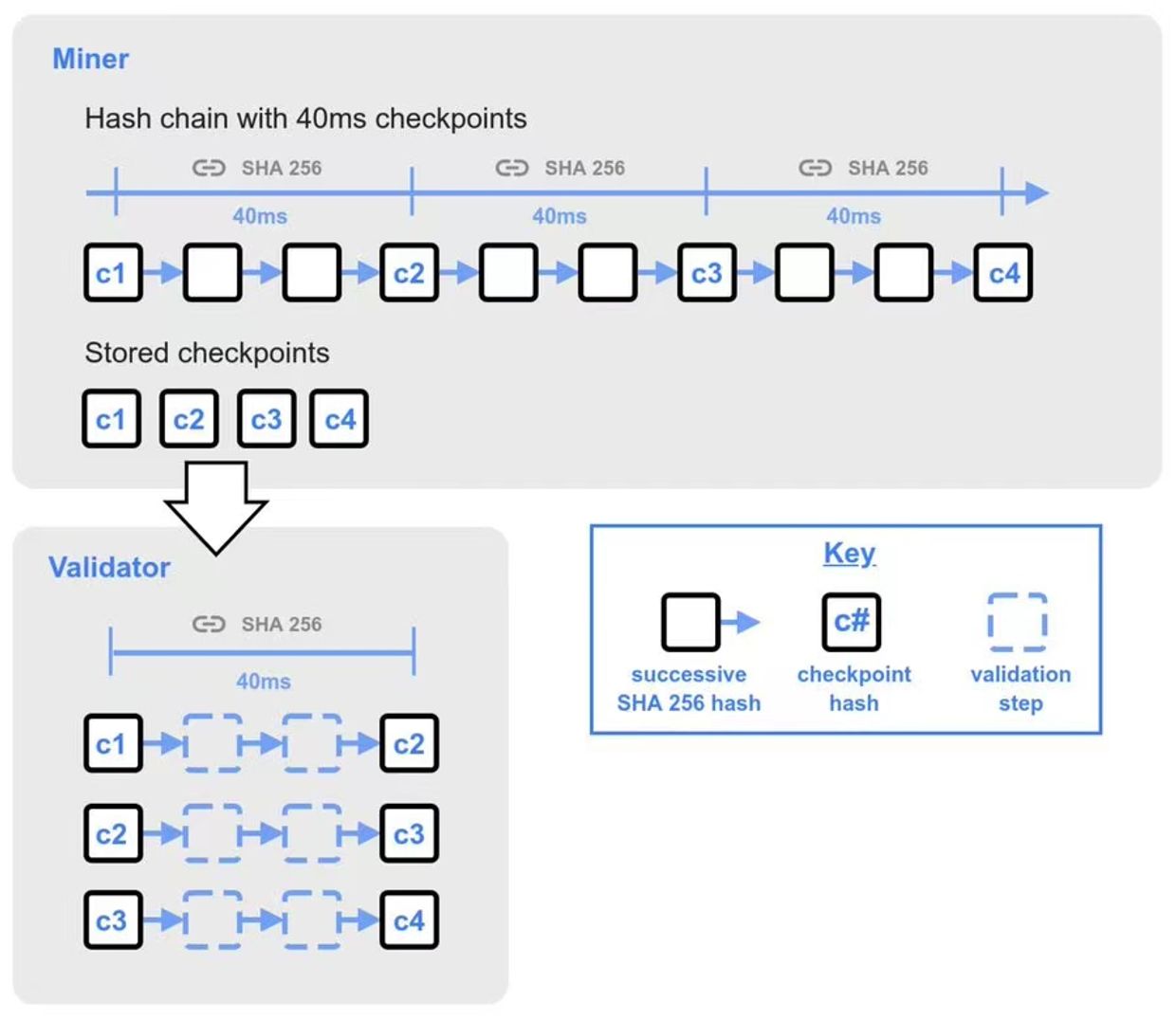
图 4:哈希链的验证过程
哈希链的种子
如果矿工或矿池拥有更快的 SHA256 哈希运算能力,他们的哈希链可能会领先于网络中的其他节点。 随着时间的流逝,这个区块速度优势可能会积累成巨大的哈希链偏移,产生的挖矿哈希与其余验证者不同步。这可能导致一系列不可控的分叉和重组现象。
为了减少这种哈希链偏移的可能性,Arweave 通过在固定间隔上使用来自历史区块的令牌来同步全局哈希链。这会定期为哈希链提供新的种子,从而使各个矿工的哈希链与一个已验证的区块同步。
哈希链种子的间隔是每 50 * 120 个挖矿哈希(50 代表区块数量,120 代表一个区块生产周期 2 分钟内的挖矿哈希数量)选择一个新的种子区块。这使得种子区块大约每~50 个 Arweave 区块出现一次,但由于区块时间存在一些变化,种子区块可能会比 50 个区块出现得更早晚一些。
图 5:哈希链种子的生成方式
以上是作者花了一些时间从 2.6 规范中摘选出来的内容,从这些可以看出,Arweave 从 2.6 开始就已经实现了低功耗,下面,更加去中心化的思想机制来运行整个网络。中本聪的愿景,在 Arweave 中得到了实践。
Arweave 2.6 。


.jpg){kind=link}