
OpenAI推出GPT-4,一分钟速览新特性
撰文:李丹
来源:
凭借 ChatGPT 掀起人工智能(AI)应用热潮的 OpenAI 发布了最新作品——GPT-4。得到这种新模型支持的 ChatGPT 将迎来升级。
美东时间 3 月 14 日周二,OpenAI 宣布,推出大型的多模态模型 GPT-4,称它可以接收图像和文本输入,输出文本,「比以往任何更具创造性和协作性」,并且「由于它有更广泛的常识和解决问题的能力,可以更准确地解决难题。」
OpenAI 表示,已经与多家公司合作,要将 GPT-4 结合到他们的产品中,包括 Duolingo、Stripe 和 Khan Academy。GPT-4 模型也将以 API 的形式,提供给付费版 ChatGPT Plus 的订阅用户。开发者可以注册,用它打造应用。
微软此后表示,新款的必应(Bing)搜索引擎将运行于 GPT-4 系统之上。
GPT-4 全称生成式预训练转换器 4。它的两位「前辈」GPT-3 和 GPT3.5 分别用于创造 Dall-E 和 ChatGPT,都吸引了公众关注,刺激其他科技公司大力投入 AI 应用领域。
OpenAI 介绍,相比支持 ChatGPT 的前代 GPT-3.5,GPT-4 和用户的对话只有微妙的差别,但在面对更复杂的任务时,两者的差异更为明显。
「在我们的内部评估中,它产生正确回应的可能性比 GPT-3.5 高 40%。」
OpenAI 还称,GPT-4 参加了多种基准考试测试,包括美国律师资格考试 Uniform Bar Exam、法学院入学考试 LSAT、「美国高考」SAT 数学部分和证据性阅读与写作部分的考试,在这些测试中,它的得分高于 88% 的应试者。
上周,微软德国的首席技术官(CTO)Andreas Braun 在德国出席一个 AI 活动时透露,本周将发布多模态的系统 GPT-4,它「将提供截然不同的可能性,比如视频」。这让外界猜测,GPT-4 应该能让用户将文本转换为视频,因为他说该系统将是多模态的,也就在暗示,不仅能生成文本,还会有其他媒介。
本周二 OpenAI 介绍的 GPT-4 的确是多模态的,但它能融合的媒介没有一些人预测的多。OpenAI 表示,GPT-4 能同时解析文本和图像,所以能解读更复杂的输入内容。
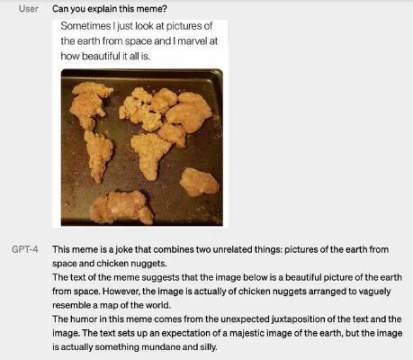
在下面的示例中,我们可以看到 GPT-4 系统如何应答图像输入内容,比如像以下截图那样解释图片的不同寻常之处、图片的幽默之处、一个搞怪图片的用意。





.jpg){kind=link}