
为什么说“小表模式”zkEVM更为高效?
前言:以太坊虚拟机是建立在以太坊区块链上的代码运行环境,合约代码可对外完全隔离并在EVM内部运行,其主要作用是处理以太坊系统内的智能合约。之所以说以太坊是图灵完备,是因为开发者可以使用Solidity语言创建运行于EVM上的应用程序,一切可计算的问题都能计算。但仅是图灵完备还不够,人们还试图将EVM封装在ZK证明系统里,但问题是封装时会产生大量冗余。Fox所发明的“小表模式”zkEVM,在保证原生的Solidity以太坊开发者能无缝迁移至zkEVM的同时,还将大幅削减封装EVM到ZK证明系统时产生的冗余成本。
EVM自2015年问世以来正在经历一场史诗级的ZK改造。这场大改造主要有两个方向。
第一个方向就是所谓的zkVM赛道,该赛道项目致力于将Application的性能提升到最优,而与以太坊虚拟机的兼容性并不是首要考虑的问题。这里有两个子方向,其一是做自己的DSL (Domain Specific Language),比如StarkWare正致力于推广Cairo语言,推广难度并不小。其二是目标兼容现有的比较成熟的语言,比如RISC Zero致力于让zkVM兼容C++/Rust。该赛道的难点在于因为引入了指令集ISA,导致最终输出的约束更复杂
第二个方向就是所谓的zkEVM赛道,该赛道项目致力于EVM Bytecode的兼容,即Bytecode级别及其以上的EVM代码都通过ZkEVM产生对应的零知识证明,这样以来原生的Solidity以太坊开发者会可以无成本迁移至zkEVM。该赛道选手主要有Polygon zkEVM、Scroll、Taiko和Fox。该赛道的难点在于兼容EVM这样一个并不适合封装在ZK证明系统时产生的冗余成本。Fox经历长时间的思考与论证,终于找到了从根本上消减第一代zkEVM巨大冗余的那把钥匙:“小表模式”zkEVM。
数据和证明电路是zkEVM生成证明的两大核心要素。一方面,在zkEVM中,证明者需要所有交易涉及的数据以证明交易带来的状态转移是正确的,而EVM中的数据量大且结构复杂。因此,如何整理和组织证明所需的数据便是构建一个高效的zkEVM需要仔细考虑的问题。另一方面,怎么通过一系列的电路约束高效地证明(或检验)计算执行的有效性与正确性,则是保证zkEVM安全性的基础。
我们首先谈第二个问题,因为这是所有设计zkEVM的团队都需要考虑的问题,这个问题的本质其实就是“我们到底要证明什么?”而目前大家对这个问题的思路都是相似的,由于一个交易(或其涉及的op-code)可能是多种多样的,直接按顺序证明每一步的操作带来的状态改变都是正确的显得不现实,因此我们需要分类证明。

图1:大表、小表两代 zkEVM解决方案
例如,我们将每次stack中元素的变化都放在一块,专门编写一个stack电路证明,为单纯的算术操作专门编写一套的算术电路等等。如此一来,每个电路需要考虑的情况就变得相对简单。这些不同功能的电路在不同zkEVM中有不同的名字,有人直接称其为电路,也有人称其为(子)状态机,但是这个思想的本质都是一样的。
为了更清楚的解释这么做的意义,我们举一个例子,假设现在要证明加法操作(将stack的上2个元素取出来,并将他们的和放回stack顶端):
假设原先的stack是[1,3,5,4,2]
则如果不分类拆分的话,我们需要设法证明进行完上述操作后stack变为[1,3,5,6]
而如果进行了分类拆分的话我们只需要分别证明以下几件事:
-
stack电路:
-
C1:证明[1,3,5,4,2] pop出2和4后变为[1,3,5]
-
C2:证明[1,3,5] push(6) 后变为[1,3,5,6]
-
算术电路:
-
C3:a=2,b=4,c=6,证明a+b=c
值得注意的是,证明的复杂程度和电路需要考虑的各种情况的数量有关系,如果不分类拆分的话,电路需要覆盖的可能性将会非常巨大。
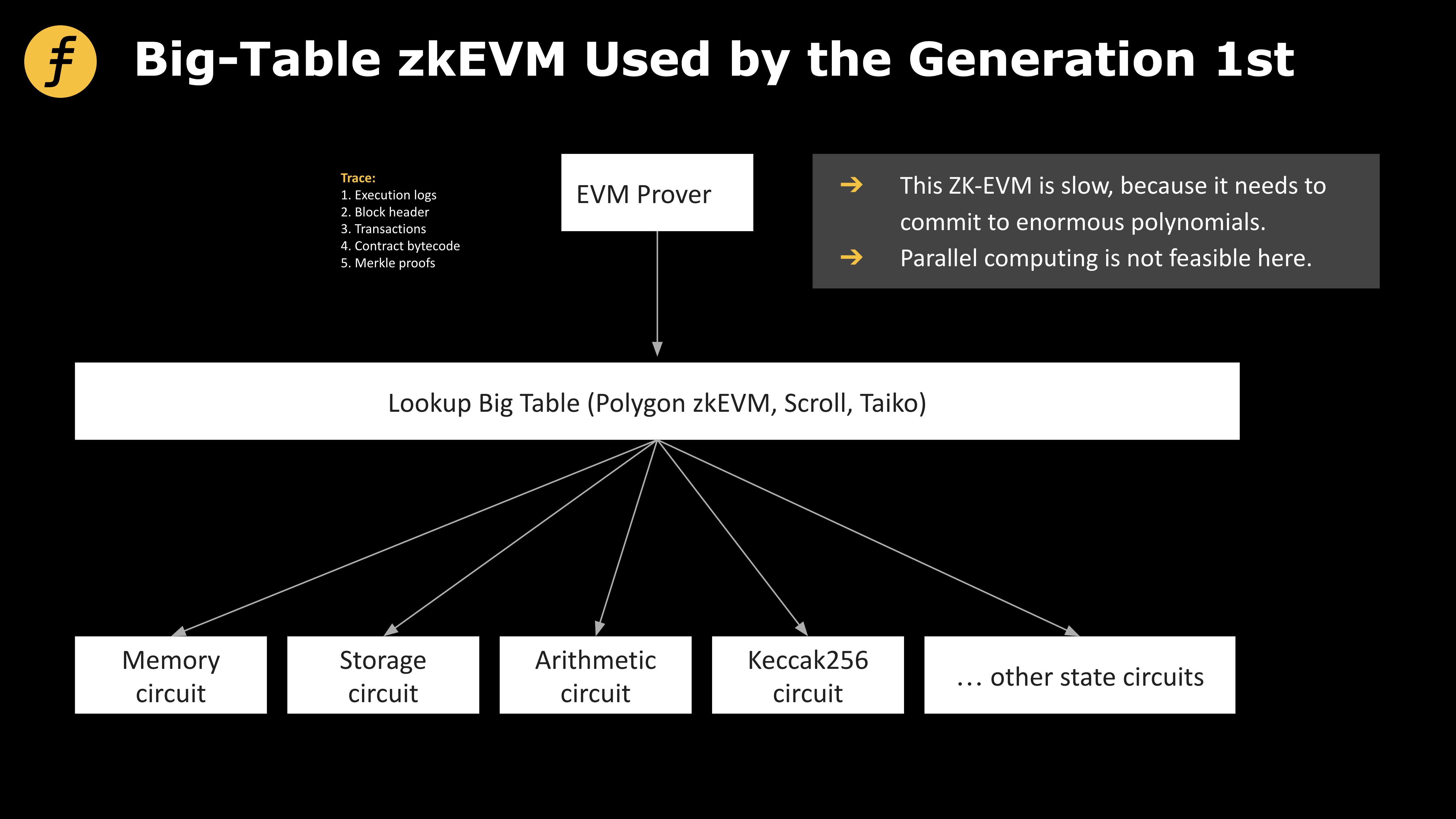
图2: 第一代zkEVM采用的大表模式
而一旦分类拆分了,每一个部分的情况将会变得相对单纯,从而证明的难度也会显著减小。
但是分类拆分也会带来其他问题,那便是不同类别电路的数据一致性问题,例如在上面的例子里,我们实际上还需要证明以下两件事:
-
C4:”C1中pop出来的数” = “C3中的a和b”
-
C5:“C2中push的数” = “C3中的c”
为了解决这个问题,我们回到了第一个问题,即我们要如何组织交易涉及的数据,下面我们接着探讨这个议题:
一个直观的方法是这样的:通过trace,我们可以拆解出所有交易涉及的每个步骤,知道其涉及的数据,并通过向节点发送请求以获得不在trace中的那部分数据,随后,我们将其如下排列成一个大表格T:
“第一步操作” “第一步操作涉及的数据”
“第二步操作” “第二步操作涉及的数据”
…
“第n步操作” “第n步操作涉及的数据”
如此一来,在上面的例子中,我们就会有一行记录着
“第k步:加法” “a=2, b=4, c=6”
而上面的C4便可以被如下证明:
-
C4(a):C1 pop 出的数和大表T中的第k步一致
-
C4(a):C3 的a和b和大表T中的第k步一致
C5也是类似的。这个操作(证明一些元素在一个表中出现过)被称为lookup。lookup的具体算法我们不在本文中详细介绍,但是可以想象,lookup操作的复杂度与大表T的大小密切相关。因此,现在我们回到第一个问题:如何组织证明会用到的数据呢?
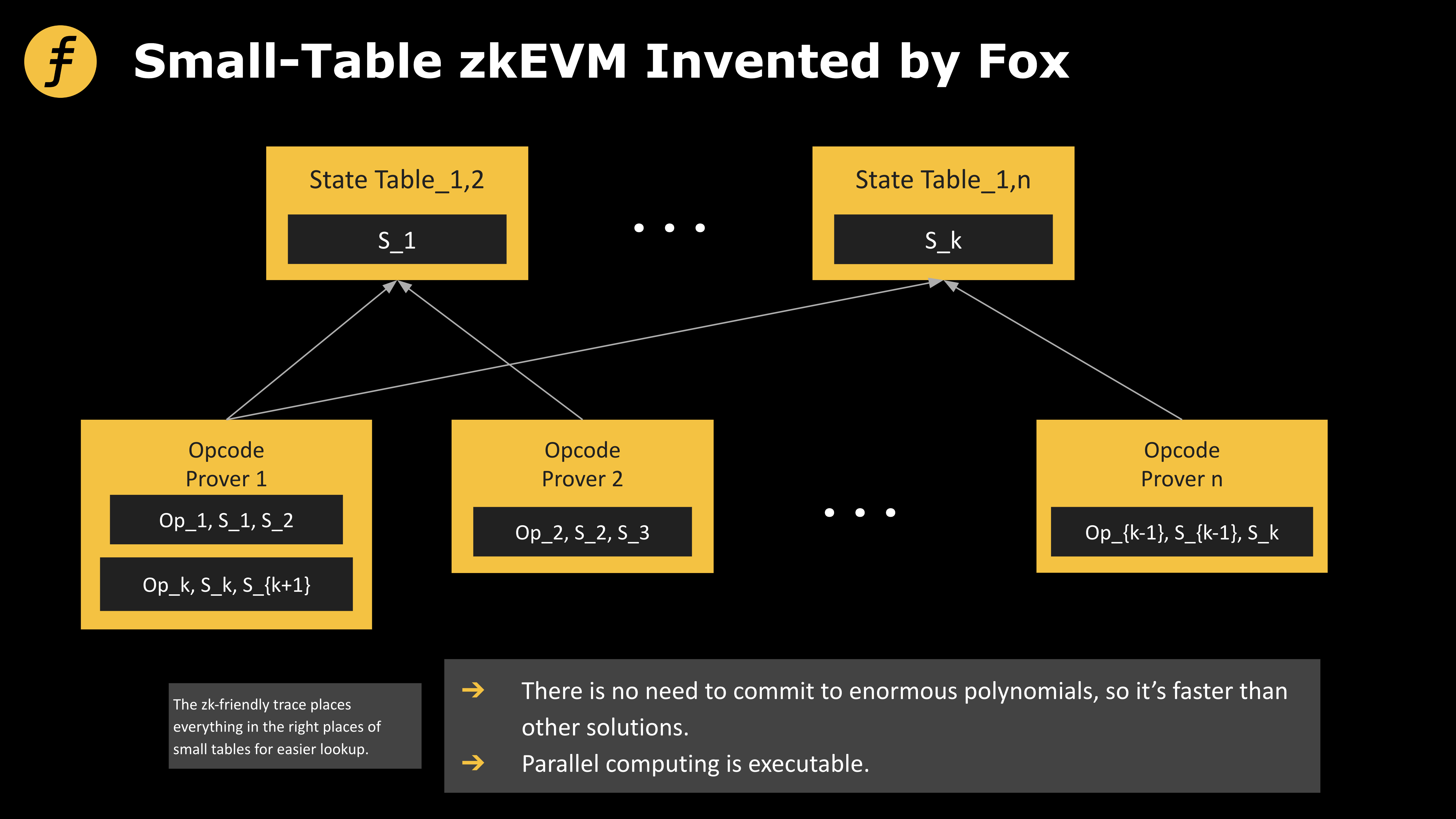
图3: Fox所发明的“小表模式”zkEVM
我们考虑如下一系列的表格构造:
表格Ta:
“类型a的第一个操作” “类型a的第一个操作涉及的数据”
“类型a的第二个操作” “类型a的第二个操作涉及的数据”
…
“类型a的第m个操作” “类型a的第m个操作涉及的数据”
表格Tb:
“类型b的第一个操作” “类型b的第一个操作涉及的数据”
“类型b的第二个操作” “类型b的第二个操作涉及的数据”
…
“类型b的第m个操作” “类型b的第n个操作涉及的数据”
…
如此构造多个小表,这么做的好处是当我们可以根据需要的数据所涉及的操作的类型,直接在对应的小表中进行lookup,如此一来,便能很大程度的提高效率。
一个简单的例子(假设我们每次只能lookup一个元素)是如果我们要证明a~h这8个字母都存在[a,b,c,d,e,f,g,h]中,我们需要对大小为8的表进行8次的lookup,但是如果我们把表分为[a,b,c,d]和[e,f,g,h]的话,我们只需要对这两个大小为4的表分别进行4次lookup就可以了!
在FOX这个layer2的zkEVM中便使用了这种小表的设计以提升效率,为了保证在各种情况下都能完备的证明,对于具体的小表拆分方式需要仔细的设计,而提升效率的关键则在于对表的内容的分类与其大小的平衡。尽管将完整的zkEVM在这个框架中实现需要庞大的工作量,我们预期这样的zkEVM将会在性能方面有突破性的进步。
结论:Fox所发明的“小表模式”zkEVM,在保证原生的Solidity以太坊开发者能无成本迁移至zkEVM的同时,大幅削减封装EVM到ZK证明系统时产生的冗余成本。这是zkEVM结构的一次重大变革,将对以太坊扩容方案产生深远影响。




.jpg){kind=link}